
The typical reading room computer in libraries, archives and often museums is equipped with a way for patrons to search and browse the institutions catalogues and digital collections. The digital collections are often rather restricted by the systems to making accessible only a few of today’s multimedia formats and documents types (for example PDF, jpeg and a few audio or video formats). For modern memory institutions it would be desirable to offer the users access to a much wider range of different types of digital object within the holdings. One of the key factors holding back agencies from giving access to these older files is that they are often so outdated that no recent application can render them in a usable or authentic way. This problem also arrises when users try to navigate archived web pages, often they are not rendered in a useful or authentic way when opened in modern web browsers. In addition to this some users may find it interesting to navigate the original digital working environments from the era of the objects that they are using for research. This would enable them to identify things such as what editing options were available or to investigate features of the old applications such as track-changes functionality. Emulation of original environments could help to extend the variety of file types that are able to be accessed in reading room environments. In order to enable seamless emulation functionality a more complex workflow is required to wrap the object and attach it to the original emulated environment (as compared to simply loading a certain file into an appropriate application as on today’s systems). This environment then needs to be powered up and the object to be loaded into it’s original creating or viewing application. Such automation is needed as it will assist the average user of a reading room digital object access machine, who is not very familiar with past GUI concepts and applications.
Past Desktop Environments
There is a large number of emulators, mostly programmed by enthusiasts, that are available as open source. Often, more than one emulator is available for emulating a certain digital ecosystem of hardware and software. For the x86 architecture in particular, there exists a wide range of commercial and free emulators and virtualization tools like VMware, VirtualBox, QEMU, Dioscuri or DosBox. In addition, with QEMU a wider range of architectures like SUN Sparc or ARM could be offered. To offer the user easy access to the different combinations of original environments and emulated hardware, at University of Freiburg we produced a small prototypical application that reads the original environment metadata from an XML file in order to provide a short description plus the machine and firmware information needed for the original environment to start.
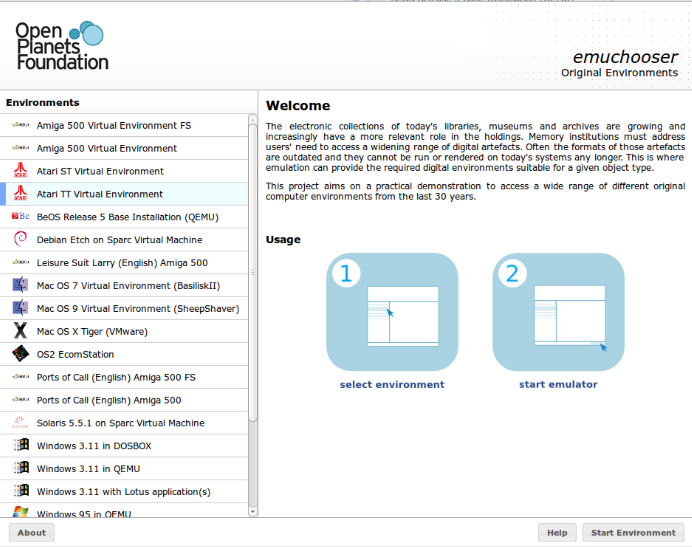
The application is executed on the Linux platform, which is a very versatile base for hosting a wide range of emulators without incurring additional licensing costs in order to run a larger number of reading room workstations in parallel. The approach was recently successfully demonstrated at the iPRES 2011 conference for Amiga, Atari, Apple MAC OS 7.X, 9 and 10.4, BeOS and a range of Windows operating systems and could be easily extended onto other emulators available for that platform. It is kind of a very light weight scripted approach compared to the more versatile (but regarding included emulators more restricted) KEEP emulation framework.
Assisted Create View
As discussed in a previous post the different involved setup procedures need to be automated as the reading room system user could not be assumed to know how to operate the different emulators and configure them according to his needs. Thus the idea is to prepare the original environment, configure the emulator and load the artefact into the started environment automatically. After loading, the user should be provided with information on how he can use the artefact or navigate the original environment (and how to shut it down after finishing his task).
To explore this a bit further different bachelor theses are being undertaken for the OPF at Freiburg University. The idea is to have different prototypes of how such a service could be run, for example to “mimic” the double-click on object and start an “automagic” loading into the proper application. These experiments do not focus on any file type detection at all during the whole procedure, but presume that this information is available or could be made available by tools discussed in the OPF blog. Coming back from iPRES there was interesting progress to be seen in the development of the TOTEM tool registry. Nevertheless the workflows need to be refined on how to use them in a library or archive reading room environment.
Open Issues
For the ongoing prototypical development it is crucial to know how this specific metadata of an object is provided. Even if the user is given the option to choose how to display a “Word Perfect 6.X” object (e.g. in Win3.11 in DosBox, Win95 in QEMU, …) information is needed to ascertain which type it is and how this information could be obtained from the archive. This is part of the service integration question, how preservation services might be provided to offer proper access to the requested objects.In a further step the integration with other preservation systems like Archivematica or exlibris’ Rosetta or Tesella’s Safety Deposit Box should be discussed and proper API’s defined and implemented. A good starting point is definitely the Planets/Scape interoperability approach for emulation services.
