
On June 7 and 8 2017, the General Annual Meeting of the Open Preservation Foundation was held at the National Library of France in Paris.

While listening to the presentations, talking with the participants and making an inventory of tools, services, workflow software and repository systems, an idea started to grow in my mind. I would like to use this blog to share that idea, and see what the community thinks of it.
Please don’t hesitate to reply to the blog post, or otherwise share your feedback.
We…
- have a lot of digital preservation (DP) software tools for DP tasks (identification, validation, metadata extraction, conversion, etc.)
- investigate significant properties and tools to extract (technical) properties
- do some benchmarking: how well do tools perform and scale in specific situations
- do some comparing of the suitability of tools for certain DP tasks in certain situations
- recognise that we can’t do preservation at the individual level, we need to cooperate
- want to exchange community best practices / profiles / policies for certain DP tasks
- want to put preservation back on the agenda of the EC, and get preservation projects funded
- have to start being practical (and thus be cool, to paraphrase Jon Tilbury)
In short, we want to know which preservation tools are best suited for certain preservation tasks in certain situations (e.g. specific datasets), or how well new tools compare to existing ones. At the moment, we have to individually find, download, install and configure tools, run them against test or real-life data, compare the outputs of the different tools, etc.
So I thought, what if we lift what we have, do and want to a higher level, rework it into a research proposal, and find funding for it? That could be EC funding (see e.g. this Dutch funding guide, including EC funding opportunities), crowdfunding or any other means to this end.
Imagine…
Imagine that we develop an open, extensible, standards-based research infrastructure for objective preservation tool testing, benchmarking and establishing community best practices. (The acronym in the title is a first attempt – I couldn’t find the words to form BPRACTICAL. Sorry Jon.) It will stimulate cooperation and help answer research questions like: given a certain set of files, which tools are best able to identify, validate, extract metadata from and/or convert that set, according to your specific needs (profile, policy)? How does this new tool I found/developed compare against existing tools? What is the best suited pipeline of identification, validation, metadata extraction and conversion tools for a certain data set? We could include emulation and other DP tasks by providing a template infrastructure ‘silo’ (see below) for additional tool categories. Moreover, by researching what we have, we will have an opportunity to find where there are gaps in the preservation ecosystem, or where there is room for improvement, and form priorities for new initiatives.
To achieve this, one of the things we need is cooperate on a standardised way of starting and sending input to tools, measuring their performance, and storing, comparing and visualising the results. This requires a community standardisation effort. No, we don’t have to redesign the tools themselves, but we do have to develop standardised APIs or e.g. WSDL documents, define some XML output collection format and implement comparison and visualisation solutions.
Good news
The good news is that we already have tools, services like PRONOM and Wikidata, and test corpora (although there’s no data like more data). We have the experience of proposing and executing projects like PLANETS, SCAPE, E-ARK and BenchmarkDP, with e.g. PREFORMA and PERICLES still running. We can build services, workflow systems and (commercial) repositories that use the tools. We also have tool sets like FITS, that harmonise tool output to FITS-XML, and tools like c3po that can gather, profile and visualise FITS-XML. We know of EUDAT and the Research Data Alliance. Several OPF members are active in the field of digital humanities, where they have a distributed research infrastructure called CLARIN, with virtual workspaces where you can fiddle with and pipeline tools? All this knowledge and technology can be reused to build our DP research infrastructure.
Street credibility
The resulting infrastructure needs to be used by the community if it is to generate community best practices. Not all possible scenarios can be tested in a project. In order to be used, the infrastructure does however need to get a certain ‘street credibility’. During the project, several practical experiments must therefore be run, resulting in (proposals for) best practices for those real-life situations.
Please note that an open infrastructure means – to me – that if must embrace open source as much as possible, but not be closed to proprietary tools and commercial organisations. Please also note that certain tools are better suited for certain tasks, and therefore the infrastructure is not intended to find ‘the best’ tool or workflow. It will help find the most suited tool and best practices for a certain situation, based on objective benchmarking in a common infrastructure – in other words, let’s BPRECISE.
The infrastructure is not a (competitor for) repository system (vendors). It will not have long-term storage functionality. It is not a preservation production environment, but a research infrastructure. The tools, workflows, benchmarks and best practices can however be used to extend and improve repository systems. Everyone should be actively involved in the development and use of the infrastructure, and can freely use the resulting infrastructure, benchmarks and best practices. Free, although we could have paid services around the infrastructure, to support its upkeep.
Sketch
If you look at my conceptual sketch of the infrastructure, you can see that there can be two types of best practice pathways: vertical and horizontal. The vertical are the result of benchmarking and comparing tools that perform similar tasks. Given your test set (compare output against your profile / policy) and available hardware (compare benchmarks), should you use e.g. DROID, FIDO or Siegfried for your file format identification purposes (or a combination)? The infrastructure may also help to find horizontal – workflow – best practices: given your situation, which pipeline of tools would be the best suited candidate?
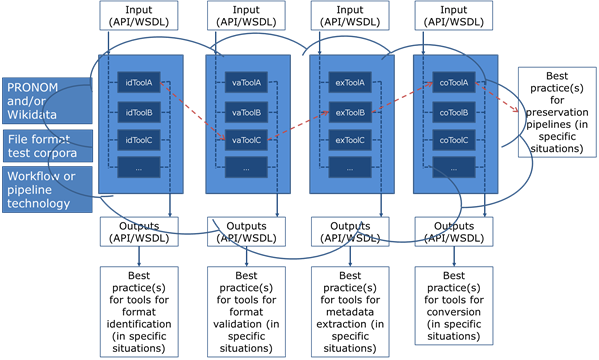
Work packages?
In terms of project work packages, we would probably need:
– WP1 [y1-4]: project management
– WP2 [y1]: input/output standardisation, generic and per DP task
– WP3 [y1-2]: underlying technical infrastructure
– WP4.1 [y2]: generic preservation task silo
– WP4.2 [y2]: comparison and visualisation suite
– WP4.3 [y2-3]: identification tool silo
– WP4.4 [y2-3]: validation tool silo
– WP4.5 [y2-3]: metadata extraction tool silo
– WP4.6 [y2-3]: conversion tool silo
– WP5 [y1-4]: community cooperation and best practice documentation
– WP6 [y1-4]: dissemination
Open Preservation Foundation
And last but not least: we already know what to write in our data management / technology sustainability plan, don’t we? Open. Preservation. Foundation. With additional funds for managing the infrastructure for at least a couple of years after the end of the project.


