
General thoughts on file format identification
File format identification is a big and complex topic. And somehow emotional. Whenever and wherever I speak about File Format Identification, there is always some well-meaning person that says: “That’s not format identification. It will only be if you add validation.” Or, alternatively: “There is no such thing as file format identification. It’s just file format guessing.”

Even so, one is likely to agree that file format identification is among the first tasks when an object steps into an archive. What about re-identification? If your object only gets identified when it steps into an archive and never again, one might miss something. With this blogpost, I want to give everybody a good reason for re-identification.
Investigation for the iPRES Poster
Micky and I have done research for an iPRES poster. It got accepted and we will present it during this year’s iPRES in Boston. Its title is:
“Time-travel with PRONOM – The fourth dimension of DROID”.
This all is based on Micky’s idea, which made me curious enough to start investigate. She had the idea after I had built a java wrapper for some identification tools, among them DROID: “Wouldn’t this tool be able to run objects through all the PRONOM signatures there have ever been and then you know since when the file format could be identified and how identification outcomes changed over time?”
We used DROID via a script which was able to run every PRONOM Signature File and a java tool which converted all the log files into convenient csv-tables (GitHub). Performance of the script was not best, therefore we only managed to examine 90 PDF-files before the deadline of the poster abstract. The 10 PDF 1.3-files of our sample could not be identified between August 2010 (sig file 38) and March 2014 (sig file 74), so I decided to look into the issue more thoroughly later.
More thorough investigation for this Blogpost
For this Blogpost, I have ran a shortened version of the script (with only some of the SigFiles) through the 20,523 PDF-files I have on my machine (a big part of those from the OPF Govdocs). 816 of them could not be identified at some point. The sample is divided as following:
| 120 | unknown | PDF files which the contemporary PRONOM SigFile cannot identify |
| 10 | misc | PDF/A, PDF/X, … |
| 12 | PDF 1.0 | |
| 28 | PDF 1.1 | |
| 177 | PDF 1.2 | |
| 162 | PDF 1.3 | |
| 103 | PDF 1.4 | |
| 23 | PDF 1.5 | |
| 10 | PDF 1.6 | |
| 161 | PDF 1.7 |
So, obviously the blind spot was true not only for PDF 1.3, but for other flavors as well. On this 816 files, I then ran the full script with all 79 SigFiles.
General Findings
From SigFile 1 to SigFile 13 (and SigFile 20, which was released earlier than 14-19) almost no PDF-File of the sample could be recognized. During the first few SigFiles, there was not yet any PDF signature pattern and between SigFile 5 and 13 it first was too strict to catch the crazy real-life PDF-files of which the sample for this Blogpost consists of.
| Version SigFile | years released | Percentage not identified |
| V1 – V13, V20 | 2005-2009 | 100% |
| V16-V37 | 2006-2010 | 35% |
| V38-V48 | 2010-2011 | 77% |
| V49-V74 | 2011-2014 | 13%-21% |
| V75-V93 | 2014-2018 | 16% |
The 16% which could not be identified form SigFile 75 on are of course the 120 PDF-files from the “unknown”-Sample. Interestingly, 74 of them could be identified during the short period from SigFile 49 to SigFile 55. All Findings see Google Docs.
Changes from SigFile 38 on: The missing carriage return
As I could not figure out the commonality between the PDF-files, which could not be identified from SigFile 38 on, I asked David Clipsham (The National Archives) for help, which he was able to provide. The following descriptions are on a great deal based on his friendly, regular help via email (I had more than one question during the course of some weeks and months).
The signature file for PDFs was changed with SigFile 38 and now expected a carriage return character at the very end of the PDF file. This behaviour was observed in the majority of the PDF files and therefore the signature was changed.
Expected behaviour:
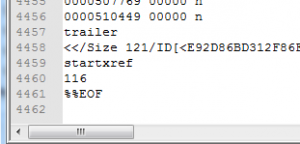
The PDF-files which could not be identified between SigFile 38 and SigFile 49, looked like this, though:
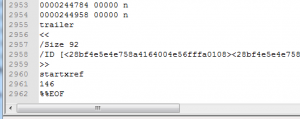
The PDF specification (chapter 3.4.4, “file trailer”) does not mention the carriage return, it just says: “The last line of the file contains only the end-of-file marker, %%EOF.”
Although the PDF reference does not prescribe the carriage return behind the EOF, this behavior is found in the vast majority of the PDF-files and when migrating the PDF-files which do not have one yet with iText or the pdfaPilot, these tools add the carriage return at the end. It seems to be an unwritten rule.
SigFile 49 and following: Carriage return no longer mandatory
Nevertheless, the PRONOM-team changed the PDF signature back, and from SigFile 49 onwards, the carriage return at the end of the file was no longer mandatory. As one can see in the General findings, the percentage of the PDF-files which could not be identified dropped significantly, from 77% to 13-21 % (depending on the exact SigFile).
SigFile 60 and SigFile 74: The PDF signature gets more flexible
From SigFile 60 on, the EOF trailer was searched within the last 0-4 bytes of the file. With SigFile 74, finally, the offset was widened to 1024 bytes, which enables DROID to identify more PDF files. This clearly is mirrored in the findings for this Blogpost, as the only PDF-files of the sample which could not be identified are from the “unknown”sample.
Special case: PDF 1.7
PDF 1.7 was released in july 2008 and there was no pattern for PDF 1.7 before SigFile 38 (released in july 2010). As the PDF 1.7 version surely was not that widespread at first, that should not have been an issue at that time. Of course, when examining the old PRONOM-signatures retrospectively, as in this Blogpost, we have to take this into consideration.
A deeper look into the sample
If you do not feel nerdy enough today to look at detailed examples, feel free to just jump to the conclusion.
Of course, most PDF-files only lack the carriage return at the very end and are otherwise fine, but there are many more interesting examples.
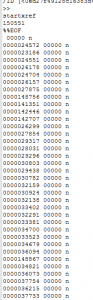
Too much junk after the PDF-trailer
Here is an example of a file trailer of a PDF-file which could only be identified after the PDF signature was extended to look for the PDF header within the last 1024 bytes at the end of the file. However, of course identification would still fail if there would be more than 1024 bytes of junk data after the %EOF tag.
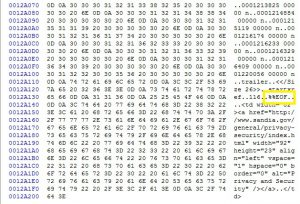
Here is another example of that sort. It looks like an updated crossref table, which is ok, but there should be an %EOF marker at the end of it (thanks to Pete May from BL for pointing this out for me).
Forever unknown
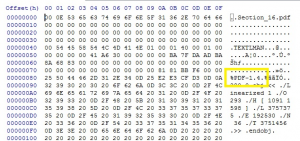
The following PDF opens without any problem in the Acrobat reader, but it was never identified by DROID during the last 17 years. The header is in the first line, but only after a fair amount of superfluous data.
And there is some data after the EOF-tag as well:
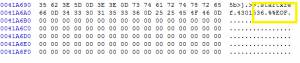
It is fair to assume that this would indeed fall under the categorie of “format guessing” rather than format identification. The Acrobat Reader, of course, tries to assume that everything that’s offerend to him is a PDF-file and tries to read it (and often succeeds, due to the flexibility of the Reader), but an identification tool might never find the PDF-header, as so much other data is preceeding it.
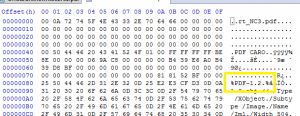
Introduced itself shortly, than vanished again
This is an example of a PDF from the “unknown”-sample, which could be identified at some point, then entered its dark age and is still there. This PDF-file could only be identified during the SigFiles 49 to 59.

Conclusion
It is likely that, if a PDF has entered your archive between August 2010 and March 2014 and the carriage return is missing at the end or there is junk data after the EOF tag or before the PDF-header, it was not identified. If no re-identification has been made since, it’s still sitting there as an fmt/unknown – or maybe as some general PDF, if the identification was then made by the extension – and will be ignored when undertaking preservation action on PDF files.
I know some people do not allow fmt/unknowns in their archive. They will only ingest known files with known formats. I know many people do not do preservation actions. We do. We have (some few hundreds of millions) fmt/unknowns in our archive and we do PDF Preservation Action. Therefore, re-identification is important for us. However, we do not do that frequently enough. Maybe I have handed in that iPRES poster and composed this Blogpost to persuade and convince myself and people like me to at least do a re-identification process before each preservation action.
As for identification: identification is difficult. Thus, there is the OPF Format Interest Group (formerly known as Document Interest Group). There is the nestor working group on format identification (nestor: german-speaking network for Digital Preservation). There is the TNA, constantly working on the PRONOM signatures, with the help of the community. And much more, of course.
Writing and deciding about a file signature pattern surely is a tightrope. If you are too strict, you miss out on too many files. If you are not strict enough, you miss-identify or have multiple matches for one file. (And we know at least one person who likes to create such files.)
Thinking about the well-meaning persons I mentioned at the beginning of this blogpost: A very loose pattern would make validation afterwards really important. A very tight pattern might even go a little bit in the direction of validation itself. This explains why the PDF signature for PRONOM has been changed and overthought so often, which has led to such diverse findings. And the process of finding the best middle way surely is not at its end yet.
If you are interested in some of the examples, I can share some requested via email ([email protected]). I am also always interested in your strange files. Of course you can re-use the script and the java-tool. If there are any questions – I am a preservation practitioner and still a newbie in writing code – please feel free to ask.


October 19, 2018 @ 1:18 pm CEST
Dear Boris,
thank you, this is interesting!
To be fair, since 2014, PRONOM can parse such PDFs just fine. It was just a “blind spot” during those 2010-2014 years. I want to emphasize another good reason to re-identify :-).
Best, Yvonne