Blogpost by Kees Teszelszky (with input of Hanna Koppelaar, Jeffrey van der Hoeven, Ben O’Brien, Steve Knight and Andrea Goethals)
The Web Curator Tool (WCT) is a globally used workflow management application designed for selective web archiving in digital heritage collecting organisations. Version 2.0 of the WCT is now available on Github. This release is the product of a collaborative development effort started in late 2017 between the National Library of New Zealand (NLNZ) and the National Library of the Netherlands (KB-NL). The new version was previewed during a tutorial at the IIPC Web Archiving Conference on 14 November 2018 at the National Library of New Zealand in Wellington, New Zealand. Ben O’Brien (NLNZ) and Hanna Koppelaar (KB-NL) presented the new features of the WCT and showed how to work collaboratively on opposite sides of the world in front of an audience of more than 25 spectators.
 |
 |
The tutorial highlighted that part of our road map for this version has been dedicated to improving the installation and support of WCT. We recognised that the majority of requests for support were related to database setup and application configuration. To improve this experience we consolidated and refactored the setup process, correcting ambiguities and misleading documentation. Another component to this improvement was the migration of our documentation to the readthedocs platform (found here), making the content more accessible and the process of updating it a lot simpler. This has replaced the PDF versions of the documentation, but not the Github wiki. The wiki content will be migrated where we see fit.
A guide on how to install WCT can be found here, a instruction video can be found here.
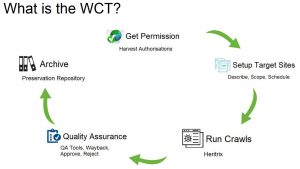
1: WCT Workflow
One of the objectives in upgrading the WCT, was to raise it to a level where it could keep pace with the requirements of archiving the modern web. The first step in this process was decoupling the integration with the old Heritrix 1 web crawler, and allowing the WCT to harvest using the more modern Heritrix 3 (H3) version. This work started as a proof-of-concept in 2017, which did not include any configuration of H3 from within the WCT UI. A single H3 profile was used in the backend to run H3 crawls. Today H3 crawls are fully configurable from within the WCT, mirroring the existing profile management that users had with Heritrix 1.

2: 2018 Work Plan Milestones
The second step in this process of raising the WCT up is a technical uplift. For the past six or seven years, the software has fallen into a period of neglect, with mounting technical debt. The tool is sitting atop outdated and unsupported libraries and frameworks. Two of those frameworks are Spring and Hibernate. The feasibility of this upgrade has been explored through a proof-of-concept which was successful. We also want to make the WCT much more flexible and less coupled by exposing each component via an API layer. In order to make that API development much easier we are looking to migrate the existing SOAP API to REST and changing components so they are less dependent on each other.
Currently the Web Curator Tool is tightly coupled with the Heritrix crawler (H1 and H3). However, other crawl tools exist and the future will bring more. The third step is re-architecting WCT to be crawler agnostic. The abstracting out of all crawler-specific logic allows for minimal development effort to integrate new crawling tools. The path to this stage has already been started with the integration of Heritrix 3, and will be further developed during the technical uplift.
More detail about future milestones can be found in the Web Curator Tool Developer Guide in the appropriately titled section Future Milestones. This section will be updated as development work progresses.
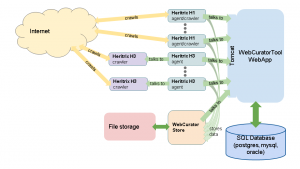
3: Diagram showing the relationships between different Web Curator Tool components
We are conscious that there are long-time users on various old versions of WCT, as well as regular downloads of those older versions from the old Sourceforge repository (soon to be deactivated). We would like to encourage those users of older versions to start using WCT 2.0 and reaching out for support in upgrading. The primary channels for contact are the WCT Slack group and the Github repository. We hope that WCT will be widely used by the web archiving community in future and will have a large development and support base. Please contact us if you are interested in cooperating! See the Web Curator Tool Developer Guide for more information about how to become involved in the Web Curator Tool community.

WCT facts
The WCT is one of the most common, open-source enterprise solutions for web archiving. It was developed in 2006 as a collaborative effort between the National Library of New Zealand and the British Library, initiated by the International Internet Preservation Consortium (IIPC) as can be read in the original documentation. Since January 2018 it is being upgraded through collaboration with the Koninklijke Bibliotheek – National Library of the Netherlands. The WCT is open-source and available under the terms of the Apache Public License. The project was moved in 2014 from Sourceforge to Github. The latest release of the WCT, v2.0, is available now. It has an active user forum on Github and Slack.
Further reading on WCT:
WCT tutorial on IIPC: http://netpreserve.org/ga2018/wp-content/uploads/2018/11/IIPC_WAC2018-Ben_O%E2%80%99Brien_Hanna_Koppelaar-Web_Curator_Tool_Tutorial.pdf
Documentation on WCT: https://webcuratortool.readthedocs.io
Documentation at NLNZ: https://digitalpreservation.natlib.govt.nz/tools-and-manuals/wct/
WCT on GitHub: https://github.com/DIA-NZ/webcurator
WCT on Slack: https://webcurator.slack.com
Recent blogpost on WCT: https://netpreserveblog.wordpress.com/2018/04/12/world-wide-webarchiving-upgrading-the-web-curator-tool/ (with links to old documentation)
Comment on twitter: