
Over the last months we’ve been working on the development of a provisional workflow for preserving the content of optical media in our collection. The main result thus far is Iromlab, a custom workflow application that streamlines the imaging and ripping process. This blogpost gives an overview of Iromlab, as well as the reasons why we created it in the first place.
The challenges
The first challenge is the sheer size of the collection: somewhere between 15,000 and 20,000 discs according to our latest estimates. Processing such volumes efficiently requires a workflow that is highly automated. Secondly, whereas the majority of optical discs in our collection are CD-ROMs, about 25% are audio CDs, which need to be processed quite differently. From the onset it was clear that the workflow should be able to handle both types of discs (we also have a significant number of DVDs as well, but these are processed in a similar manner to CD-ROMs). Finally, it is crucial that the disc images remain linked (through metadata) to their respective records in our catalogue. A particular quirk here is that in most cases, a catalogue record does not describe an individual disc. Often the discs are supplemental to a physical (paper) book. In that case the catalogue record describes the book, with a metadata field indicating that the book contains, for example, a CD-ROM. Another common situation is that the catalogue record describes multiple discs. For example, it may describe a language course that is made up of one DVD, 2 CD-ROMs and 3 audio CDs. In all these cases, there is a one-to-many relationship between the catalogue record and the entities (books, optical discs) that it describes. Because of this, it is important that the workflow retains a record of the sequential order of discs within one catalogue record.
Disc robot
The level of automation that is required for this job implied we would need to use some kind of disc robot. Based on earlier work by colleagues at the British Library, we bought an Acronova Nimbie machine (NB21-DVD type) for evaluation. The first thing that became obvious was that the software bundled with the machine has many limitations, making it unsuitable for our needs. Somewhat disappointingly, the bundle does not include any tools or an API to operate the disc loading mechanism (load, unload or reject a disc). However, a quick test with the dBpoweramp batch ripper software (part of dBpoweramp, which had been on top of our shortlist of candidate tools for audio ripping) revealed that this software includes command-line driver tools for loading, unloading and rejecting. This makes it possible to operate the disc robot from a custom-built script (which wraps around these command-line tools). It also enables one to use the machine with pretty much any extraction or audio ripping software that has a command-line interface: after loading a disc, the disc robot’s optical drive can be accessed like any ordinary (internal or external) drive. This sparked the development of Iromlab (Image and Rip Optical Media Like A Boss), a custom workflow application to streamline the imaging and ripping process.
Main workflow components
The workflow is built around a number of tried and tested software components. For the disc type identification it uses cd-info, which is part of libcdio, the "GNU Compact Disc Input and Control Library". Extraction of data tracks from CD-ROMs and DVDs is done with IsoBuster. Audio ripping is done with dBpoweramp. Since dBpoweramp only has a graphical interface, we contacted its author, and through a small development contract with the KB he wrote a command-line tool for the core ripping software. This enabled us to to integrate dBpoweramp into the workflow as well. Ripped audio files are verified for completeness using either Shntool (WAVE format) or flac (Flac format). ISO images are checked with Isolyzer. Finally, operation of the disc robot is done using the dBpoweramp driver tools.
Architecture
The workflow (which is written in Python) integrates the above components. The figure below gives an overview:
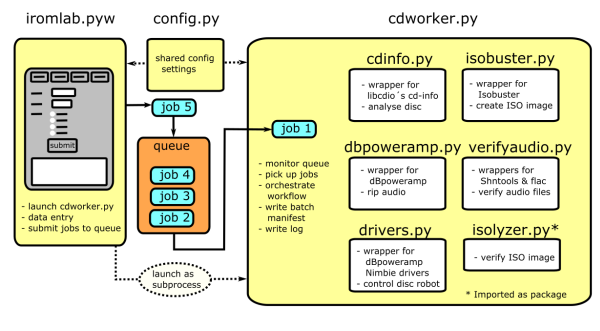
In short, Iromlab consists of a main module (iromlab.pyw) that defines a graphical interface that is used to enter data about each disc. For each disc the entered data are sent as job files to a file-based processing queue. These jobs are monitored by a worker module (cdworker.py), which orchestrates the main heavy-lifting (disc identification, imaging, etcetera). The jobs are processed in "First In First Out" order. As the physical discs are inserted into the machine in the same order, this ensures that the workflow keeps track of the relationship between the discs and the entered data (in the absence of data entry errors!). Since the worker module runs as a subprocess (separate thread from the data entry interface), new discs can be loaded continuously while the imaging/ripping process is ongoing. The overall goal was to make the workflow as simple as possible to use for an operator, which meant that manual data entry is reduced to a minimum.
Batch structure
All output of an Iromlab session is written to a batch. Each disc is represented by a directory which contains the extracted data (ISO image, WAVE/Flac files), log files of the extraction software, cd-info output and a SHA-512 checksum file. In addition, each batch has a batch manifest, which is a comma-delimited file that contains all information that is needed to process the batch into ingest-ready Submission Information Packages (SIPs) further down the processing chain. This includes a simple "success" flag that indicates whether the imaging of a disc was successful. Finally, the batch contains a log file with detailed output about the individual processes in the workflow. For an example of the batch structure, check out this small online demo batch. Note that for copyright and file size reasons, all ISO and FLAC files from the original batch are replaced by empty (zero-byte) files in this demo.
Data entry
Upon startup, Iromlab launches a simple graphical interface that is used for data entry. An operator then presses a button to create a new batch. Once the batch is initialised, the following fields need to be entered for each disc:
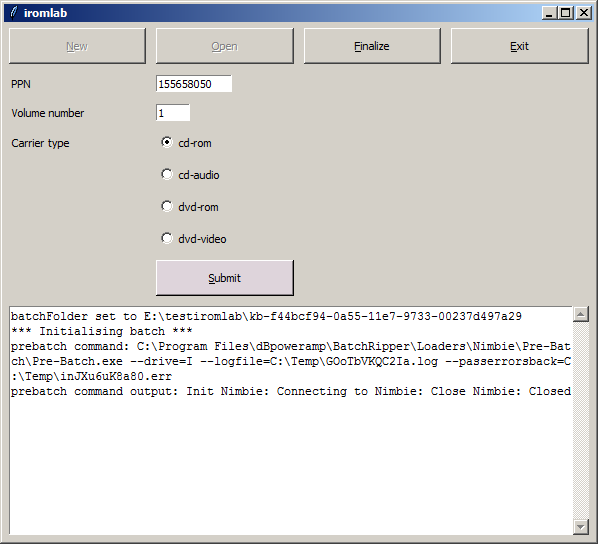
Here, PPN is the identifier of the catalogue record that is associated with the disc. Volume number defines the sequential order in case multiple discs are associated with one record (e.g. a CD box set). Note that Carrier type does not influence the imaging or ripping process; it is only used to describe the disc at the metadata level. After pressing "Submit", Iromlab looks up the entered PPN identifier in the KB catalogue using an SRU query, and then prompts the operator to confirm the publication title that was returned:
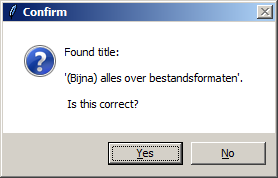
After confirming this, Iromlab prompts the operator to insert the disc into the disc robot:
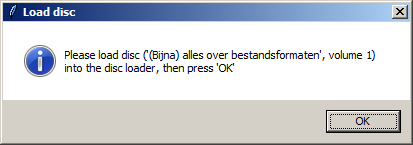
This second prompt tries to enforce a fixed processing order (i.e. enter the data first, and then insert the disc), which reduces the risk of synchronisation errors between the jobs queue and the stack of physical discs in the disc robot. After pressing "OK", the job is added to the processing queue.
 Iromlab in action; disc robot on the left.
Iromlab in action; disc robot on the left.
Processing a disc
Meanwhile the worker module continuously scans the processing queue for job files. Once it picks up a job, it reads the information from the job file, and tries to load a new disc. The processing of each disc then involves the following steps:
- Analyse the disc with cd-info.
- Record information about the sector layout of the physical disc (this is needed to ensure ISO images extracted from CD-Extra / Bluebook discs are accessible).
- Rip any audio tracks to WAVE or FLAC; extract data tracks to ISO images.
- Record information about the extraction process (logs, exit codes).
- Check the integrity of the extracted/ripped files.
- Record fixity information (SHA-512 checksums).
- Record any information that is necessary further down the processing chain for the creation of ingest-ready SIPs.
- Add an entry for the disc to the batch manifest.
Further processing of the batch
In order to create ingest-ready SIPs from a batch, some further processing is necessary. In particular:
- The integrity of the batch needs to be verified (i.e. is the batch complete, were all discs imaged successfully?).
- Any discs that have problems need to be removed from the batch. Since in our case we decided that each SIP will contain all discs that belong to a catalogue record, this also means that for each problematic disc, all discs that belong to its corresponding catalogue record are removed (i.e. moved to a separate "error batch").
- If the batch passed the verification step, it can be transformed into ingest-ready SIPs.
The above steps are outside of Iromlab‘s scope, but they are covered by the separate omSipCreator tool. This is a work in progress that still needs some refinements, and it might be the subject of a follow-up blog.
Using Iromlab outside the KB
Iromlab is tailored specifically to the situation at the KB, and it is not meant to be a general-purpose workflow solution. Nevertheless, others might find (parts of) the software useful. For instance, it would be quite straightforward to adapt those parts of the software that query the KB catalogue to other institutional catalogues or databases. Also, even though Iromlab is tailor-made to a very specific combination of hardware and software, most of the software dependencies are implemented using simple wrapper modules. Adding new ones for alternative (imaging or ripping) tools would be pretty easy.
Documentation
User documentation for Iromlab is available here. It includes a User Guide, as well as detailed instructions on how to install the software, and how to setup and configure IsoBuster and dBpoweramp.
Acknowledgements
Thanks are due to dBpoweramp creator "Mr. Spoon" for his work on the dBpoweramp command-line tool, and for allowing us to re-distribute the binaries. IsoBuster‘s author Peter van Hove is thanked for some modifications he made to IsoBuster‘s command-line interface.

July 24, 2017 @ 10:27 pm CEST
Superb write-up. Thank you.