
Motivation
When it comes to PDF validation, the world is suddenly very small. Although many digital archives have to deal with PDF (rather than PDF/A, at least not from the start), there is only one PDF-validator that I know of and that’s JHOVE.
Having worked with JHOVE for six years now, I feel I know JHOVE and its capabilities (and limitations) pretty well. But I felt I had to re-evaluate if there really is no other PDF-validator out there. (PDF, not PDF/A, there are a plethora of PDF/A validators out there). But is this really true or has the world out there changed while I was busy sitting inside doing my JHOVE-validations?
Talking to other PDF-savvys, we thought about the possibility to use PDF/A validators for PDF validation, just configure them in a way that they will ignore the PDF/A-only rule and check for PDF-syntax only. As we are currently using veraPDF 1.8.4 and pdfaPilot 7 for our digital Archive, we chose these two.
veraPDF
Presenting my idea to Carl from the OPF, I almost immediately got the answer:
“Well, but veraPDF is not a PDF validator.”
“Ok, I know, but let’s try nevertheless!”
We created a light-weight policy that would check for one entry in the information dictionary only, just to see if veraPDF would be able to parse the PDF or not.
Choose Configs” -> “Policy Config”
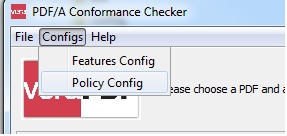
Click on the “+”-label and then choose e. g. “Information Dictionary” and check for the title.
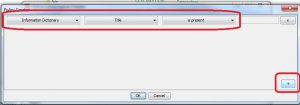
After clicking of OK, the policy needs to be saved somewhere as a “*.sch”-file. Executing a folder of PDFs with this policy still will check for PDF/A-1b-compliancy, there seems to be no way to prevent this.
At least there are three different kinds of findings:
- PDF/A compliant
- not PDF/A complian
- Failed to parse

This might be interesting, but just because veraPDF was able to parse a PDF does not mean it considers it to be a valid PDF. Or to have a valid PDF syntax. I did the test with the 89 PDFs Micky Lindlar and I created for our iPRES paper and 88 of them are not well-formed syntactically. We know that for a fact, as we have manipulated them ourselves, purposefully not following the PDF specification. Nevertheless, veraPDF was able to parse 26 of them.
So, that’s fine, it’s no fault of a PDF/A validator to be able to parse invalid PDF files. But this means to me that there is no back door to divert veraPDF from PDF/A validation and use it for a PDF syntax check only.
pdfaPilot
Using the pdfaPilot was a little bit more promising from the start, as the support team created a configuration file for us which explicitly checked the syntax only. Of course most of the PDFs from our iPRES-sample were too broken for pdfaPilot to generate a report, as it usually does, even if a PDF cannot be converted or is not a valid PDF/A. So we redirected the output of the console to txt-files.
30 of the 89 could not be analyzed, because pdfaPilot could not even open them. That’s understandable, as some of the files indeed were so broken and invalid, that no viewer could open them. The others could be parsed. pdfaPilot found syntax problems in each one of them, usually one of these:
Syntax problem: Indirect object “endobj” keyword not followed by an EOL marker
ID in file trailer missing or incomplete
This is pretty promising, but still I am not really satisfied, for the following reasons:
The PDFs of the iPRES paper all hurt one specific rule. For example, there are seven files that have an invalid File header, e. g.
| Correct would be: %PDF-1.4 | What’s wrong with it? | pdfaPilot |
| %PDF-2.4 | Invalid major version | Could not swallow that |
| %PDF-1.9 | Invalid minor version | Did not realise the header was wrong |
| %PDF-14 | Dot missing | Could not open file |
| %PDF1.4 | Hyphen missing | Could not open file |
| %PDF.1.4 | Dot instead of hyphen | Could not open file |
| %1.4 | „PDF“ is missing | Could not open file |
| %âãÏÓ | Junk data | Could not open file |
I certainly do not blame pdfaPilot for not being able to open our really badass-header-PDFs. Still, it would have been perfect if there would be an error message like “invalid PDF header”, at least for the one PDF pdfaPilot was able to open, the one with “%PDF-1.9” (maybe they thought one day a PDF 1.9 version would be available).
With the trailer problems, pdfaPilot was doing better, at least with those which it could open. It throws the error:
ID in file trailer missing or incomplete
or
The document structure is corrupt.
That’s fine. I am under the impression that the pdfaPilot would realize if there is something wrong with the file trailer, which is very useful in our daily preservation life, as this happens quite often if a file is not completely uploaded/downloaded and there is a missing chunk.
To get an idea what pdfaPilot would do with PDF files from the real life, I additionally tested 19 files which were considered to be not well-formed by JHOVE.
Again, two really corrupt files which could not be opened by a viewer could not be opened by pdfaPilot. This brings delight to my heart: I always wanted some really fast, easy and automatic workflow which just checks if a file can be opened. Obviously, I can use this pdfaPilot-configuration to do so (assuming the following tests will bring the same output). That’s already helping a lot.
As “PDF validation” might be a difficult expression to start with, it might not even be a valid statement that pdfaPilot does not perform PDF validation. What does PDF validation mean here? As a matter of fact, it does perform a sort of PDF validation in terms of PDF renderability, which is an important part of PDF validity, if not even the most important part, for me as a Digital Preservation Manager.
As for “ordinary” malformed files, PDF validation in terms of PDF specification validation, pdfaPilot cannot be misused as a PDF validator. For those files it will still check PDF/A compliance and run tests to check whether or not fonts are embedded etc. and generate its usual reports (instead of redirected output from the console).
Conclusion
There is no tool apart from JHOVE that validates PDF files. But at least pdfaPilot can be used to find the “really broken” PDF-files fast and easy, those which cannot be opened by standard-PDF-viewers like Adobe Acrobat. And, I must stress, this is something that JHOVE cannot. As we have analyzed in our aforementioned paper, JHOVE has considered two files from the iPRES sample as well-formed and valid which could not be opened by Adobe Acrobat. Furthermore, a PDF which is not well-formed does not necessarily have displaying issues. So that is one additional piece of information which I can use in my daily workflows.
Neither veraPDF nor pdaPilot can serve as PDF validators. But at least, pdfaPilot does a great job detecting “really corrupt and broken” PDF files.

April 27, 2018 @ 10:04 pm CEST
I read PDF validation topic and come to know pdfaPilot.Internet Explorer 10 technical support
December 22, 2017 @ 12:22 pm CET
Hi Boris,
nice, thank you for your answer.
veraPDF: I heard about the disussion to extend the veraPDF parser to check file and document structure and find it very interesting. I guess, full PDF-validation is not what I expected, anyway, but a low-level-structure-check which indicates if sth. is wrong with the file structure. The iPRES testset has all kinds of file structure problems, so it’s perfect for testing, indeed.
JHOVE: You are right, we are at it. The iPRES testset was part of it, as is this test, the work of the OPF DIG around the error messages and all the other examinations about JHOVE from 2016 and 2017 (concerning TIFF, WAVE, JPEG, GIF, you name it). We are just at the beginning, I guess.
Thank you for the hint about the error messages, I did not know that “Indirect object “endobj” keyword not followed by an EOL marker” is a PDF/A-validation error. As it is introduced with “Syntax problem”, I figured it’d be more generic.
There still is a lot to be done.
I am very glad about veraPDF and use it as a PDF/A-validator. As we mostly receive PDF-files, though, I still depend on JHOVE a lot. And that’s ok. Improving JHOVE is one of my professional goals.
Thanks a lot!
Happy holidays, Yvonne
December 22, 2017 @ 12:14 pm CET
Thanks for a very interesting post and in particular a very nice test corpus.
Speaking on behalf of veraPDF dev team, I confirm the words of Carl that veraPDF is not a PDF validator. And the main reason is that the scope of complete ISO 32000-1 (and now also ISO 32000-2) validation is so huge that is doesn’t make much sense. It is more realistic to find those parts which are most important in practice. For example, in the preservation world these, I guess, would be:
– low-level syntax, file structure, document structure, content stream checks (Sections 7.3, 7.5, 7.7, 7.8 of ISO 32000-1)
– embedded font validation
– image compression validation
– PDF/A validation
veraPDF covers only the last item and provides the plug-in mechanism to do extra checks of fonts, images and other embedded third-party formats. We are also discussing the possibility to extend veraPDF parser to check file and document structure.
When it comes to JHOVE, I think, the main question is what exactly it validates, as the documentation is not providing many details here. So, your test collection is an excellent way to find this out via black box testing approach.
On a technical side, I find the discussion around the error messages
Syntax problem: Indirect object “endobj” keyword not followed by an EOL marker
ID in file trailer missing or incomplete
a bit confusing. These are typical PDF/A validation errors, as ISO 32000-1 does not impose any conditions on the EOL after ‘endobj’ or on the presence of ID in the document trailer (unless the document is encrypted).