
For those of you thinking “YES! A #wtfpdf post on why PDF is the worst date ever” … I’m sorry to disappoint. This blog post is actually yet another installment of the (JHOVE) validation error series I’ve been writing over the years. It’s quite literally about the PDF-HUL-133 error message “Improperly formed date”. Since the error is very straightforward and (spoiler alert!) ranked low in impact by others , this should be a good example for beginners to follow along and maybe get to know some new pdf-Tools and commands along the way. You can find a very simple synthetic file containing the error here. While the file itself is synthetic, meaning I hand-wrote it, the error is based on one encountered “in the wild”.
I’ll be describing the process using a methodology I’ve introduced at ipres2023. If you’re interested to read the paper behind it, you can do so here. An abridged version of the workflow presented in this blog is also available on COPTR / COW.
Validation Error
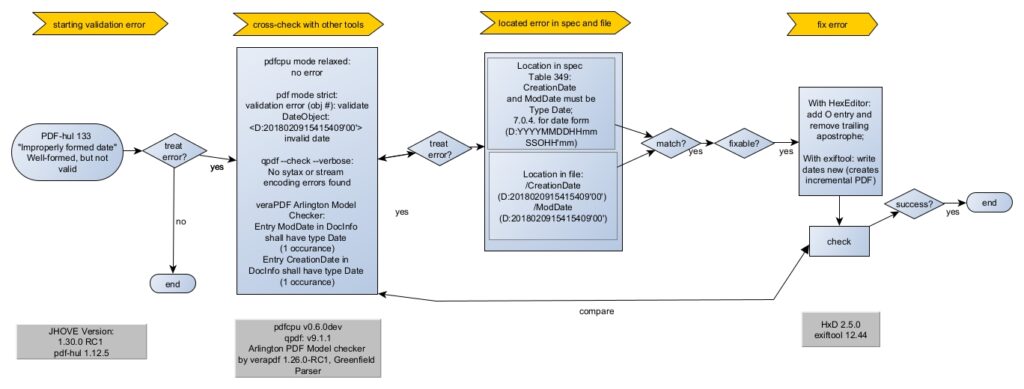
The analysis starts with the “Well-Formed, but not valid” message for PDF-HUL-133 error “Improperly formed date”. Table 1 contains the version of JHOVE that was used for validation.
Cross-check with other tools
It’s always good to get a second or third opinion. As mentioned in previous posts, pdfcpu and qpdf are two of my standard go-to tools. The new kid on the block for me is the veraPDF Arlington Checker. The Arlington PDF Model itself is a machine-readable data model of all pdf objects. Written by PDF mastermind Peter Wyatt, the model is available on github and while it is structured and documented very well, it is not easy to use for those who feel more comfortable with a graphical user interface. The veraPDF Arlington Checker closes that gap by wrapping the model in the familiar interface of veraPDF. Even though it’s currently “only a release candidate“, it works great and I would encourage everyone to try it out!
As Table 1 shows, JHOVE, pdfcpu in strict mode and veraPDF Arlington all agree that something is awry with one or several date objects. While JHOVE gives us the offset (547) pdfcpu and veraPDF Arlington give us the more helpful object id (#6). Arlington is particularly helpful in its error message, telling us that there are actually two errors – one in ModDate and one in CreationDate – and in both cases, the type of the value is wrong: “has type String instead of type Date”.
| Tools and Version / Mode | JHOVE v1.30.0 RC-1 PDF-hul 1.12.5 | pdfcpu v0.6.0 dev / relaxed mode | pdfcpu v0.6.0 dev / strict mode | qpdf v9.1.1 | veraPDF-Arlington-1.26.0 RC1 |
|---|---|---|---|---|---|
| Command | GUI | pdfcpu validate -mode relaxed inputfile | pdfcpu validate -mode strict inputfile | qpdf –check –verbose inputfile | GUI |
| Result | ErrorMessage: Improperly formed date ID: PDF-HUL-133 Offset: 547 | OK | validation error (obj#:6) (try -mode=relaxed): pdfcpu: validateDateObject: <D:2018020915415409’00’> invalid date | No syntax or stream encoding errors found | Specification: PDF Reference 1.4, Clause: DocInfo-ModDate, Test number: 8 Deviation 1 occurrences: Entry ModDate in DocInfo shall have type Date; ADocInfo containsModDate == false || ModDateHasTypeDate == true root/FileTrailer[0]{FileTrailer}/Info[0](ADocInfo 6 0 obj){Info} Entry ModDate in DocInfo has type String instead of type Date Specification: PDF Reference 1.4, Clause: DocInfo-CreationDate, Test number: 8 Deviation 1 occurrences: Entry CreationDate in DocInfo shall have type Date; ADocInfo containsCreationDate == false || CreationDateHasTypeDate == true root/FileTrailer[0]{FileTrailer}/Info[0](ADocInfo 6 0 obj){Info} Entry CreationDate in DocInfo has type String instead of type Date |
Locate error in file and in specification
Personally, I find it much easier to spot errors by looking at the obj instead of the offset, so I’m thankful for the verbosity of tools like pdfcpu and veraPDF Arlington. Tools like qpdf can show you the output of an obj based on it’s id.
qpdf --show-object=6 hello_world_invalid-date.pdf
<< /CreationDate (D:2018020915415409'00') /ModDate (D:2018020915415409'00') >>So now we know that there are two dates – CreationDate and ModDate – both with the same value – (D:2018020915415409’00’). As the Arlington Checker error message informed us, this appears to be the wrong type (string instead of date). Here, we need to look at the specification.
ISO3200-2:2017 specifies the date type in section 7.9.4. In Table 2 I loosely summarized the spec breakdown of the date type and compared it to the two dates found in obj 6.
| D: | YYYY | MM | DD | HH | mm | SS | O | HH’ | mm | ‘ | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ISO3200-2:2017 specification | D: (mandatory) | year (mandatory) | month 01-12 | day 01-31 | hour 00-23 | minute 00-59 | second 00-59 | relationship of local time to UT, expresed by +, – or Z | offset from UT in hours 00-23, followed by an apostrophe | offset from UT in minutes 00-59 | optional ‘ Not included in ISO32000-2, but versions up to 1.7 defined a date string to include the terminating apostrophe. |
| CreationDate in sample file | D: | 2018 | 02 | 09 | 15 | 41 | 54 | Missing | 09′ | 00 | ‘ |
| ModDate in sample file | D: | 2018 | 02 | 09 | 15 | 41 | 54 | Missing | 09′ | 00 | ‘ |
Table 2 allows us to easily spot the error – the “O” entry is missing. As the spec tells us, the “O” entry designates the relationship of the datetime given to Universal Time. Expected were “+”, “-” or “Z”, but none were found. In same cases you may be able to figure out the correct entry needed from context such as a correctly formed XMP metadata date or the authors given country of residence. In other cases this might be impossible.
Fix it!
There are a few ways to fix this. In the interest of remaining as close to authenticity as possible, a fix is ideally “minimally invasive”. In my opinion this would rule out things like migrating the object to PDF/A or even fixing the date in Adobe Acrobat and saving it, as those options significantly change the internal structure of the file. However, that is just my personal opinion and I know many choose to go down those paths. I would prefer one of two options instead.
Option 1: Exploit the trailing apostrophe
Option 1 works with this specific file because there is one byte we don’t really need and one byte missing, which equals out. However, this would not work if more than just the O entry are missing or if the trailing apostrophe wasn’t there to begin with. Option 1 also cheats in some ways, as it makes use of the back- and forward compatability of PDF readers and acknowledges the fact that version-exact PDF behavior pretty much never exists. The fix only works though, if you know what the missing piece of information, in this case the offset, should be.
Going back to Table 1 we can see that our dates (D:2018020915415409’00’) have a trailing apostrophe after the offset mm, which has been removed with PDF2.0 ISO32000-2:2017. The standard recommends PDF readers to accept both variants, as non-ISO specs defined the apostrophe following the offset-mm as part of the syntax. On the other hand, those specs also contained rather unclear statements such as “The prefix D:, although opotional, is strongly recommended.” (see PDF Reference fifth edition – Adobe Portable Document Format Version 1.6).
If we know what the offset should be, e.g. because we have context information about the timezone the author works in, we can enter the correct sign such as +. Since we’ve added one byte, we need to remove one as well in order for the cross-references to still work correctly. This is where the optional apostrophe at the end comes in:
Before: (D:2018020915415409'00') - 28 44 3A 32 30 31 38 30 32 30 39 31 35 34 31 35 34 40 49 27 30 30 27 29
After: (D:20180209154154+09'00) - 28 44 3A 32 30 31 38 30 32 30 39 31 35 34 31 35 34 2B 40 49 27 30 30 27
The fix can be easily completed in a Hex Editor of your choice. Validating the resulting file returns no validation errors with pdfcpu in modes strict and relaxed, qpdf and veraPDF Arlington checker. However, JHOVE still reports the same PDF-hul-133 error. This is because JHOVE implements the old spec only, thus requiring the apostrophe after the mm-offset. I’ve opened up an issue on github, asking to address this.
Option 2: Incremental update containing date fix
While option 1 only changed a few bytes of the PDF file, this option adds something to the file. The good thing about incremental updates is that they are fully reversible and no existing bytes are changed, updates are only appended. This option also works if you don’t know what the offset value O should be. We can make use of the fact that, as shown in Table 2, we can form a valid date by only including the string up to the last position known. So, instead of (D:2018020915415409’00’) we could also just say (D:20180209154154).
Exiftool can be used to update the dates as incremental updates. Note that exiftool doesn’t need the PDF date type format as an input. It will parse it internally to the correct format.
exiftool -PDF:ModifyDate="2018:02:09 15:41:54" -PDF:CreateDate="2018:02:09 15:41:54" hello_world_invalid-date.pdfThis added an incremental update to the end of the file. Going into details on incremental updates is a bit out of scope here – it’s just important that you know that they may add more complexity to the file, but can be easily rolled back using tools like pdfressurect or pdftool.
After the update the new obj 6 included in the incremental update now looks like this:
<< /CreationDate (D:20180209154154) /ModDate (D:20180209154154) >>
The fixed file successfully passes validation with all tools listed in Table 1, including JHOVE.
Impact on rendering / file behavior
So how severe is this error? First off, there are different places in a PDF where dates can be included. Exiftool does a pretty good job at reading out all dates.
exiftool -time:all -G -a -s hello_world_invalid-date.pdf
[File] FileModifyDate : 2024:05:12 13:02:42+02:00
[File] FileAccessDate : 2024:05:12 14:55:07+02:00
[File] FileInodeChangeDate : 2024:05:12 14:42:00+02:00
[PDF] ModifyDate : 2018:02:09 15:41:54
[PDF] CreateDate : 2018:02:09 15:41:54Please note that exiftool only interprets as much of the date as it can. So the output for the two PDF dates will be the same for hello_world_invalid-date.pdf in its original form as well as after fix option 2.
For our test file, the File section shows the file system level metadata associated with the file, while the PDF section shows the dates found within the PDF itself in obj 6. Another date type that might be present is XMP-level date information. While ISO32000-2:2017 expects many metadata fields formerly found at the “PDF-level” such as Author, Creator and Subject to now be included in their respective xmp or dc Entries, CreationDate and ModDate are still valid entries in the PDF Info dictionary.
Different PDF readers take different approaches as to what and how “ModifyDate” and “CreateDate” are shown. Images 1 -3 below summarzie how Adobe Acrobat Pro, Foxit PDF Reader and Sumatra PDF Reader show the dates of the file hello_world_invalid-date.pdf in it’s original state, after fix option 1 and after fix option 2.
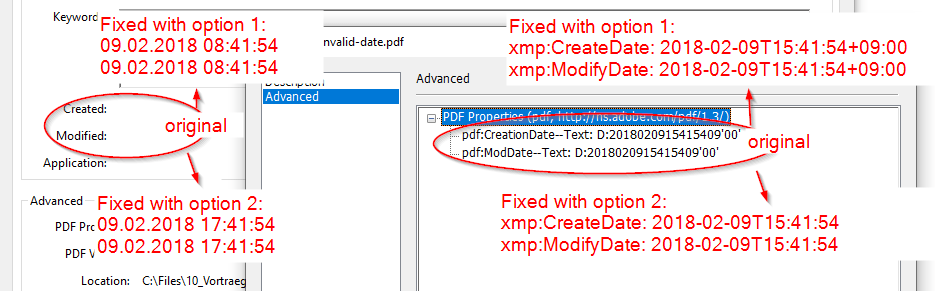
In the original form, Adobe Acrobat shows no dates in the File –> Properties “Created” and “Modifed” sections. Under “Additional Metadata” -> “Advanced” the PDF-Date values are shown as included in the obj. Fix option 1 results in the “Created” and “Modified” sections in the Properties being populated. The values are not taken directly as found in the value, but Acrobat takes the UT offset into consideration and calculates the time based on my machine’s time zone (currently CEST). So 15:41 at UTC+9 = 06:41 at UTC = 08:41 at CEST. In fix option 2 we cut the entire offset, so the “Created” and “Modified” dates are based on the assumption that the PDF dates are at standard value, which is UTC. This then just needs to be calculated to CEST – so 15:41 UTC is shown as 17:41 (CEST).
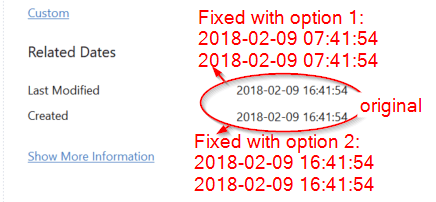
Foxit does something similiar, but apparently doesn’t take summer time into consideration. The offset of my machine is therefore not +2 to UTC but only +1. This turns Acrobats 08:41 fix option 1 time to 07:41 fix option 1 time in Foxit. In fix option 2 17:41 turns to 16:41 accordingly.
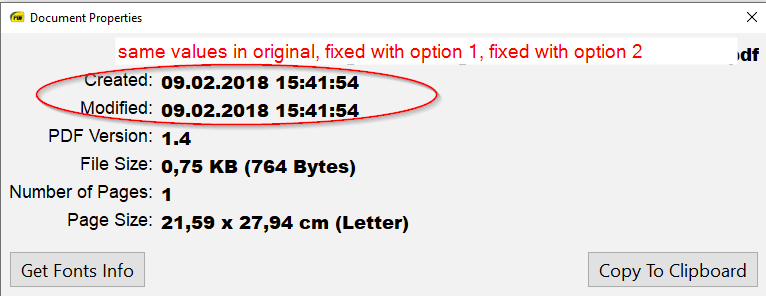
In case dates and times confuse you as much as they confuse me (I regularly show up at wrong times for meetings because I can’t do the calculations right), you might want to turn to Sumatra PDF Reader. This slim tool doesn’t make any assumptions when it comes to time zones and just shows the created and modified dates as given in the PDF. Since in all 3 variations – the original, fix option 1 and fix option 2, the D:YYYYMMDDHHmmSS part of the date was present, Sumatra shows the same dateTime stamp for all three files.
To fix or not to fix – that is the question
As shown in Images 1-3 there’s no way to tell what exactly a PDF reader is going to actually show when it comes to dates. Furthermore, there’s no way to tell what PDF reader the user is going to use. Since the error has no major impact on a file’s rendering, I would rate this error as low and choose not to fix it.
In other words: this date with PDF’s “improperly formed dates” may have been enjoyable and there might have been some lessons learned, but I think we’re just going to stay friends and not take this any further.
Workflow Summary

May 13, 2024 @ 6:41 pm CEST
We LOVE this series, Micky! Thank you for the newest addition 🙂