
Hi, this is my first blog post in which I want to introduce the project I am currently working on: Flint.
history
Flint (File/Format Lint) has developed out of DRMLint, a lightweight piece of Java software that makes use of different third party tools (Preflight, iText, Calibre, Jhove) to detect DRM in PDF-files and EPUBs. Since its initial release we have added validation of files against an institutional policy, making use of Johan’s pdfPolicyValidate work, restructured it to be modular and easily extendible, and found ourselves having developed a rather generic file format validation framework.
what does Flint do?
Flint is an application and framework to facilitate file/format validation against a policy. It's underlying architecture is based on the idea that file/format validation has nearly always a specific use-case with concrete requirements that may differ from say a validation against the official industry standard of a given format. We discuss the principal ideas we've implemented in order to match such requirements.
The code centres on individual file format modules, and thus takes a different approach to FITS; for example – the PDF module makes use of its own code and external libraries to check for DRM. Creating a custom module for your own file formats is relatively straight-forward.
The Flint core, and modules, can be used via a command line interface, graphical user interface or as a software library. A MapReduce/Hadoop program that makes use of Flint as a software library is also included.
The following focuses on the main features:
Flint-the-API
The core module provides an interface for new format-specific implementations, which makes it easy to write a new module. The implementation is provided with a straight-forward core workflow from the input-file to standardised output results. Several optional functionalities (e.g. schematron-based validation, exception and time-out handling of the validation process of corrupt files) help to build a robust validation module.

Visualisation of Flints core functionality; a format-specific implementation can have domain-specific validation logic on code-level (category C) or on configuration level (categories A and B). The emphasis is on a simple workflow from input-file to standardised check results that bring everything together.
Policy-focused validation
The core module optionally includes a schematron-based policy-focused validator. 'Policy' in this context means a set of low-level requirements in form of a schematron xml file, that is meant to validate against the xml output of other third-party programs. In this way domain-specific validity requirements can be customised and reduced to the essential. For example: does this PDF require fonts that are not embedded?
We make use of Johan’s work for a Schematron check of Apache Preflight outputs, introduced in this blog post. Using Schematron it is possible to check the XML output from tools, filtering and evaluating them based on a set of rules and tests that describe the concrete requirements of *your* organisation on digital preservation.
Flint-the-toolbox
Aside from its internal logic, Flint contains internal wrapper code around a variety of third-party libraries and tools to make them easier to use, ensuring any logic to deal with them is in one place only:
* Apache PDFBox
* Apache Tika
* Calibre
* EPUBCheck
* iText – if this library is enabled note that it is AGPL3 licensed
These tools all do (a) something slightly different or (b) do not have full coverage of the file formats in some respects or (c) they do more than what one actually needs. All these tools relate more or less to the fields of PDF and EPUB validation, as these are the two existing implementations we're working on at the moment.
Format-specific Implementations
- flint-pdf: validation of PDF files using configurable, schematron-based validation of Apache Preflight results and additionally internal logic and all tools in the list above to focus on DRM and Wellformedness
-
flint-epub: validation of EPUB files using configurable, schematron-based validation of EPUBCheck results and additionally internal logic and all tools in the list above to focus on DRM and Wellformedness
NOTE: both implementations are work-in-progress, and should be a good guide for how to implement your own format-validation implementation using Flint. It would be easy to add a Microsoft Office file format module that looked for DRM etc, for example.
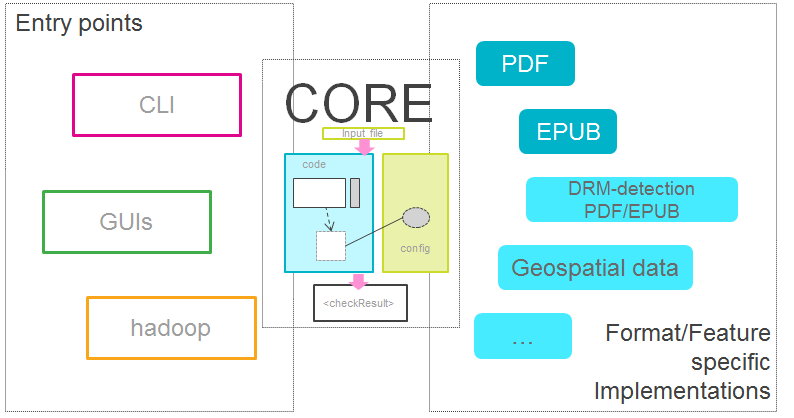
Visualisation of the Flint ecosystem with different entry points and several format/feature-specific implementations (deep blue: existing ones, baby blue: potentially existing ones); the core, as visualised in Figure 1 connects the different ends of the ‘ecosystem’ with each other
how we are using it
Due to the recent introduction of non print legal deposit The British Library is preparing to receive large numbers of PDF and EPUB files. Development of this tool has been discussed with operational staff within the British Library and we aim for it to be used to help determine preservation risks within the received files.
what’s next
Having completed some initial large-scale testing of a previous version of Flint we plan on running more large-scale tests with the most recent version. We are also interested in the potential of adding additional file format modules; work is underway on some geospatial modules.
help us make it better
It’s all out there (the schematron utils are part of our tools collection at https://github.com/bl-dpt/dptutils, Flint is here: https://github.com/openplanets/flint), please use it, please help us to make it better.

