
"Digital preservation is more than the technical preservation of a file … it is also about providing readers with the context surrounding it to promote authenticity."
Principle 2, Requirement 8 of the Archives New Zealand Electronic Recordkeeping Metadata Standard asks for seven mandatory elements to be captured:
- A unique identifier
- A name
- Date of creation
- Who created the record
- What business is being conducted
- Creating application and version
Additionally, three elements are asked for when an action is performed on a record in Requirement 9, these are:
- The date of the action
- Identification of the person or system undertaking the action
- What action was undertaken
These metadata elements serve to create a context around a document that:
“…enable an organisation to reconstruct some context, enabling it to defend the record’s authenticity. Without these minimal metadata elements, reconstruction of a complete record is impossible.”
Without an Electronic Document and Records Management System (EDRMS) some of this data is difficult to capture accurately with files out of context; format identification tools not returning Creating Application and Version, and Author/s, Business context and other values dependent on being associated with a bitstream in some way.
Within my current work responsibilities; attempting to capture as much contextual metadata as possible from a shared drive – that is, a hard disk, shared by multiple users in the absence of a formal records management system; I want to question how much metadata is available for us to capture from digital files in isolation. Is it enough to help describe context?
We rely on characterization tools and metadata extractors to pull out information when we accession files – file format, format characteristics, and checksums. This is often technical, file level technical metadata, but author(s), comments, title, etc. – the contextual information – is it there? And are we able to retrieve that as well?
Starting from scratch
There are a number of tools that help us to discover technical and file level metadata. They all have their own benefits, be that simplicity of use, number of parsers available to them, output formats etc. None of these tools collect metadata consistently. DROID 6.1 CSV output, for example, can’t access all file system date metadata we require, returning only the last modified date. Even the Windows standard DIR command on the command line requires it be run three separate times to return modified, created and last accessed dates; all useful to provide context, however, having to aggregate this information via multiple processes isn’t helpful.
What I’m beginning to discover is that we haven’t a single tool to pull all our metadata together into a single useful form, and beyond whoever is writing these tools; users’ basic knowledge about how to access various streams of metadata and what metadata actually exists is abstracted away. Where do we find it all?
To show potential sources of metadata in two common Windows XP environments, I’ve created the following diagram:

An explanation of the data available in these slightly varying environments follows:
File System
At the file system level, three pieces of metadata we’re looking for are the aforementioned timestamps belonging to a file:
- Creation
- Last Accessed
- Last Modified
While these are returnable in an NTFS file system, a brief look at this table of metadata support on Wikipedia, and a corresponding footnote shows that in the FAT32 file system, Last Accessed and Created timestamps are only ‘partially’ available. That is, when enabled in DOS 7.0 and higher.
NTFS supports file owner metadata – Who created the record? The FAT32 file system does not. In an NTFS file system this is the ‘username’ of the person who created the record – on my current system that corresponds with ‘spencero’.
The degrees of variability in metadata support in file systems and presumably methods of accessing that information creates an issue for preservation tools dealing with legacy systems at the lowest level of access. As such the first point of call for any all-encompassing metadata extractor might be to identify the file system it is operating on and then tailor its extraction of metadata, and the range of what it extracts, according to that context. That, or systems should provide other ways of recording and returning this information.
NTFS Alternate Data Streams (ADS)
On top of the file system data we might be interested in extracting already; NTFS disks support Alternate Data Streams (ADS). Although this is a feature of the file system itself I’ve separated it in the diagram above as it is also closely associated with a file stream.
Alternate Data Streams are hidden streams of information that can be associated with any file on an NTFS file system. The streams are binary and therefore can be of any level of complexity, from plain text to a complete binary object. Any number of streams can be associated with a single file. When ADS are associated with a file it doesn’t change the file’s checksum – this makes it particularly difficult to monitor any changes, or indeed, even keep track of the existence of these objects.
To create an alternate data stream you can run notepad, as follows:
Notepad.exe ADSFile.txt:ADSStream.txt
This will add a stream to ADSFile.txt called ADSStream.txt and open a new text document where you can add as much data as you like to it and save it. You won’t be able to see this additional file in a directory listing but you can open it using the same command used to create it. Providing the file remains on an NTFS based system, or is transferred between NTFS systems, the stream will remain attached to the primary file object.
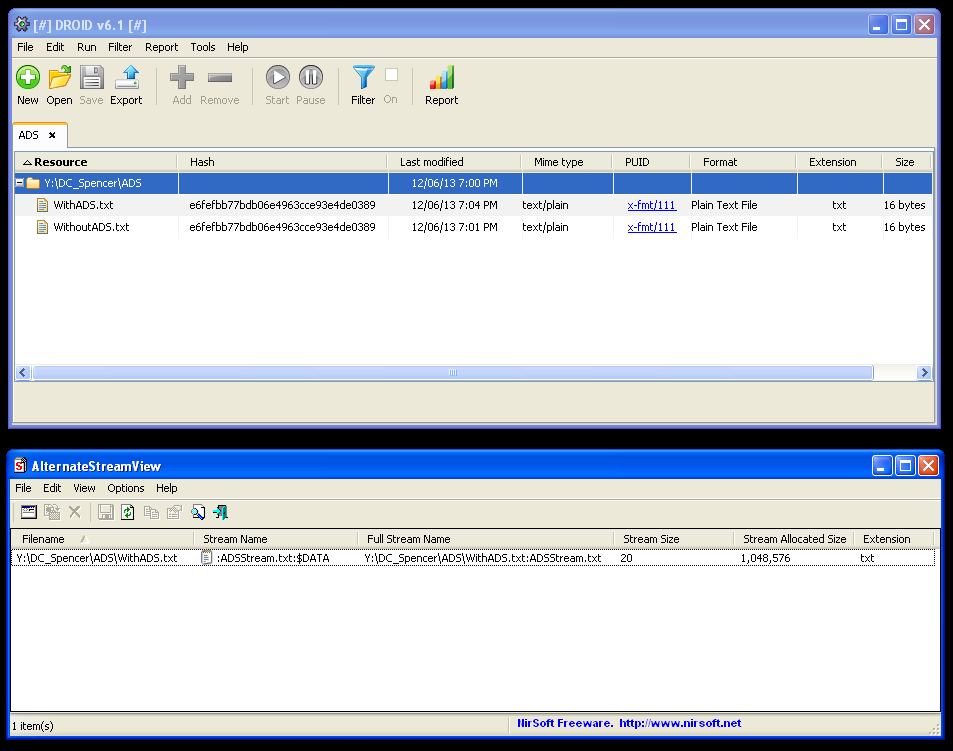
Legitimate uses of ADS are the summary properties, (Title, Subject, Author, Category, Keywords, Comments, Source and Revision Number), that belong to plain text files, and other file types in Windows that don’t implement alternatives (discussed later). Populating this information via Windows properties dialogs will generate several alternate data streams that you can view or identify in applications such as Microsoft's Windows Sysinternals Streams or Nirsoft’s AlternateStreamView and AlternateStreamDump.
A potentially significant amount of information that is stored with Internet Shortcut files is the favicon that belongs to its associated website. You can access this by reading the ‘:favicon’ stream attached to the shortcut’s LNK file. The intellectual value of a favicon might be significant to some, and could be lost in a transfer between incompatible file systems.
Because of the flexibility, and arbitrary nature of the data in ADS they are considered a potential security threat with the opportunity for hackers and other users to store malicious information or code within them. As some web servers can, or have previously been able to serve alternate data streams from objects they deliver to the end-user, this may be of particular concern to webmasters.
Stepping away from the security risk, the most important thing we must observe about ADS is that they can store anything. This has implications for the files we accession; for the information we might not spot before it hits our repositories; the information that is lost in transfer to or from our repositories; or indeed the information and context we can gain from files with associated ADS. With no change to the file checksum – identifying ADS requires the incorporation of specific tools, such as those listed above, to our digital preservation workflows. I am not aware of any tools in the mainstream digital preservation toolkit that identify and extract these files as a matter of course.
Compound Storage
Microsoft defines compound storage as a file system within a file. This enables it to overcome the “challenges of efficiently storing multiple kinds of object in a single document”. According to Microsoft, compound storage provides a single interface for accessing many different objects within a single file. Although a Microsoft abstraction, among other benefits, such as improved performance when storing multiple object types, compound storage, or compound files are platform independent, enabling them to be used across different file systems, unlike Alternate Data Streams.
As well as platform independence, of particular interest to digital preservation should be the inclusion of property sets about compound objects – metadata.
Two sets of properties which closely resemble that found in basic Alternate Data Streams, and begin to expand on them are Summary Information and Document Summary Information (and User Defined property sets).
In the former property set we find Title, Subject Author and a handful of other potentially useful name, value pairs. In the latter, such fields as Category, Manager, and Company. User Defined fields within Document Summary Information enables users to create any properties – as described by Microsoft – usually named properties created by a user.
The range of metadata we can write and therefore extract becomes quite expansive, and can potentially become incredibly descriptive – especially for the purpose of providing context.
Apache Tika is capable of extracting summary and extended property sets in compound objects, as such, it is an important utility that should be used in standard digital preservation workflows. Tools like the National Library of New Zealand Metadata Extractor and ExifTool are useful for extracting summary properties. DROID 6.1 is capable of reading compound files to provide more accurate identification results.
File stream
The file stream, or bitstream is the part of the file we all know and love (well, some of us!) You can do anything with a file at this point; the arbitrary structure of a binary object allowing for many different representations of information. We can take advantage of this to make a file as simple or as complex as required with as little or as much associated metadata to make them self-descriptive.
This is the majority of the information we’re pulling out of the objects, either directly or through interpretation, using tools like JHOVE, ExifTool, or Jpylyzer.
Formats such as FLAC which supports up to 128 different types of metadata block, but currently define seven, practically; demonstrates how extensively metadata can be incorporated into a bitstream.
Any format can be written to provide the ability to store any amount of metadata. PNG defines its own textual ‘chunks’. MP3 incorporates the ID3 and ID3v2 metadata containers. HTML provides limited metadata in META tags within the head of the document; but can also be enriched with more expressive metadata standards such as RDFa (Resource Description Framework – in – attributes). Formats can also be written to support broader metadata standards such as XMP (Extensible Metadata Platform) – formats such as PNG, PDF, GIF and MP4 providing mechanisms of supporting this. We simply need the parsers to understand it and extract it.
In terms of expressivity, many discrete files may be able to contain enough information to provide the context we’re looking for, but this would require creating applications to have knowledge of our requirements – this is not always likely. It shouldn’t, however, prevent us from extracting it as often as we find it.
What’s left and is it enough?
Understanding the location of information and how to extract it can only help us moving forward. Going back to the question behind this blog and asking whether we can extract enough information from a file in isolation to help describe context – then I’m still not convinced – certainly about whether we have all the necessary tools for the job.
We can extract a lot of information about individual files from the metadata sources that I’ve described here but the questions that still concern me are:
- Is that enough for digital preservation?
- What other metadata sources am I missing? (e.g. resources in DLLs, EXEs?)
- What other tools can we make use of?
- What tools are available that agglomerates this data?
- What are we doing about context?
- Even in EDRM systems are we doing enough? (e.g. collecting creating application and version information)
Digital preservation is more than the technical preservation of a file. As described in the introduction it is also about providing readers with the context surrounding it to promote authenticity. First we need to identify and collect the information, and then, given the sheer number of files that we’re dealing with and the numerous potential sources they are likely to come; we require robust and scalable ways of doing that. We might get this information from a file in isolation, but it’s not guaranteed to exist, and if not, what are we doing in the community to analyse and understand the systems digital objects are found in and belong to?
What are your experiences in answering some of the questions I have raised above?



August 9, 2013 @ 3:42 pm CEST
I'm staying neutral as I think it's more important for me to help us as a community come to a consensus on the way forward, rather than just chip in my opinion. I guess I also feel that it's more important that we agree on a particular way forward (whatever that way is) as opposed to not getting agreement and remaining fragmented. If the community makes the decision we're much more likely to get the weight of support behind it that is needed to make a difference.
August 9, 2013 @ 10:03 am CEST
Yes, I think a published roadmap of how these things fit together, along with Carl's testing framework, would help draw developments together. Some tutorials on how to write and use additional modules might help too.
I do appreciate what you are trying to do by staying solution neutral, but I really don't think we can maintain that for long. We really need people to propose concrete preferences so we can discuss it. I have spent time with the source code of all the tools (DROID, JHOVE, NZME, FITS, Tika & JHOVE2), attempting to fix bugs and/or add modules. Based on that experience, I am advocating one particular approach. I am happy to compare my experience others, and as long as any decision is based on open discussion I will happily acquiesce.
August 8, 2013 @ 10:55 am CEST
To make this happen we need a number of things to come together.
A lot of the typical funding in this field comes in the form of short projects. This tends to result in the creation of new tools. I think it's important that we're able to tap into that to help with what we've been discussing, but also to avoid the creation of completely new tools that again become unsustainable.
August 8, 2013 @ 10:38 am CEST
The characterisation hackathon was good, and I think everyone felt the current situation was untenable, but it wasn't clear what to do next. There was a push on FITS, which was also good, but I see FITS and most of JHOVE2 as functioning at a different level to Tika/NZME/JHOVE/DROID. The latter are pure Java tools to produce single results, whereas the former invoke all sorts of tools and work to produce multiple results, then resolve and/or expose the conflicts.
JHOVE is a particularly important case. It is deployed at a wide range of institutions (I believe), but not being funded directly, is acknowledged to be so out of date as to be misleading in cases, and the main developer currently has a job doing something else. I don't know how widely NZME is deployed, but it has similar problems. I would like us to start by folding those together as Preservation-Tika (Pika?) modules, but I'd really like the existing developers and users blessing, and to know that they would be happy to shift any contributions to the new project and mark the older ones as being superceded.
Later, we could look at JHOVE2/FITS and how to resolve the fact that they do very similar jobs. We could also look at wrapping DROID as a Tika format Detector (I already have a prototype for that). In contrast to the JHOVE/NZME work, none of this need require folding in those existing projects as they are mostly well maintained and supported.
Maybe this relationship between the tools, and this kind of rough roadmap, could be published and supported by OPF, putting Fido and Jpylyzer in context. We could try to define some kind of sign-up procedure where folks could comment on the roadmap and commit some degree of effort to it, and OPF could perhaps offer grants for specific chunks of work?
August 8, 2013 @ 9:56 am CEST
I agree that we need some more coordination to make the little bits of DP community effort more effective and more sustainable. Almost all of the tools created in our community have an initial burst of effort (often finite project funding behind it) and then development dries up. It's difficult for a lone institution to keep investing in tool maintenance and enhancement. Clearly we need a different approach.
I was hoping to begin to move us towards more coordination via the characterisation hackathon that SPRUCE hosted earlier in the year, but again, it's keeping the momentum going that is proving difficult. A regular hackathon would be one way to help, but so far its not looking great for the follow up. Sign ups for the hackathon I've put together at iPRES are thin on the ground.
Perhaps a remote hackathon approach would be worthwhile? OPF has been doing some thinking on ways of structuring this kind of thing.
Paul