
This blog post is introducing CiTAR – Citing and Archiving Research, a three year Baden-Württemberg state project, which is developing infrastructure to support computer assisted research. One major outcome of this project are means to publish, cite and provide long-term access to virtual research environments.
As an example for perpetual access to software-based research resources, we have used the outcome of the SlaVaComp project (2013-2015), which created an electronic meta glossary of regional and diachronic varieties of Church Slavonic – a language that was used in the Orthodox Slavia between the 10th and 16th centuries. Until the creation of a digital database, researchers had to consult printed dictionaries, which meant that even simple lookups could take a tremendous amount of time. Fifteen printed Church Slavonic and Greek glossaries with various regions of origin were combined into an easy-to-use online web-based application.
As the support for the underlying server operating system will expire in the near future, the SlaVaComp service’s future is uncertain. Even if the operating system is upgraded to the next long-term support version, there is no guarantee that any other software dependency e.g. the database remains compatible or has long-term security support, crucial for a public online service. Furthermore, it is highly unlikely that former employees could adapt the service to a modern software stack, mainly because they have left after the project ended and with them most of the specific knowledge about the software they created.
This fate is shared by numerous software developments that emerge from scientific projects. The costs for maintaining a server and the software after the end of a project are usually not covered, especially if these projects are only of interest for a small and specialized research community. Leaving an unmaintained, outdated machine connected to the internet poses a latent and increasing security risk.
Submitting a Virtual Research Environment to CiTAR
The first CiTAR workflow covers the publication process of a virtual research environment. As every research domain uses different software stacks, specific ways of configuration and usage patterns, a generic and fully automated approach is required, ideally treating all VMs the same way. Hence, we focus on the preservation of a full computer (or a set thereof) and treat the inner mechanics of the machine’s service as a black box. As a base preservation technology emulation (resp. virtualization) is used based on the Emulation-as-a-Service (EaaS) framework with a corresponding preservation strategy for generalized/normalized disk images and VMs.
As a part of this process, a CiTAR publisher is able to upload an image (e.g. a VM) which is then analyzed and technically normalized, to ensure compatibility with the emulation or virtualization infrastructure and its long-term preservation options. Furthermore, the user has to describe the machine’s service and how it can be used.
In a further step, the publisher is able to test run the machine and to further customize it to improve usability, e.g. change passwords, auto-start applications etc. All changes are tracked and result in versioned revisions of the machine. Finally, a Handle.net persistent identifier is assigned to the published machine, which points to the archived machine’s landing page.
On-Demand Server-Access
A published, archived and in particular citable research environment requires (long-term) access. The handle associated with the archived VM redirects the user to a landing page describing the virtual environment and possible interactions. Most of these machines target small audiences and won’t be accessed often, therefore, a visitor of the respective landing page initiates the startup of the instance. Provisioning and startup takes between takes at least 30 seconds, depending on the machine’s size and complexity.
The main challenge for access workflows is the security of archived machine. As these machine has been archived to remain in its original state, a (permanent) internet connection could be harmful.
In order to provide (secure) network access, all archived machines are deployed in their own private network. The CiTAR gateway acts as a bridge between the private network and the user’s network. Depending on the security requirements and/or access infrastructure the we offer currently three different network access options:
Port forwarding
For local network deployments, network ports of an emulated server can be forwarded to a user-accessible network. For instance, the SlaVaComp landing page provides a Connection Information window, allowing the user to connect directly to the web application running on the internal port 8080.
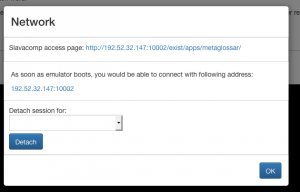
CiTAR SlaVaComp Landingpage Example (hdl: 11270/52fd18be-44ec-4b1d-94b4-887fa139142815)
SOCKS
If the machine provides multiple services (TCP ports), a the SOCKS5 mode can be used. The Connection Information window will display necessary information for a local proxy configuration. Optional simple! password protection is possible.
After setting up the SOCKS proxy, the SlaVaComp example will be available under its original IP http://10.0.2.100 and expose port 80 and 8080.
CiTAR SlaVaCom Landingpage (SOCKS mode) (hdl: 11270/62fd18be-44ec-4b1d-94b4-887fa139142815)
Local-mode
In some scenarios, e.g. remote access, a fully private connection is necessary. Additionally, to use an archived machine with current research software multiple (local) network ports might be required. For this, CiTAR offers a local connection mode. The user has to install a small program (available for Linux, MacOS and Windows) which registers a CiTAR network URL-handler. Alternatively, source code and automated builds are available on Gitlab. Installation is only necessary once.
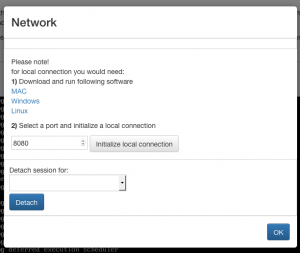
The user needs to choose a local port the connection should be bound to (e.g. 8080). A click on initialize local connection will start the local proxy (or will trigger a system dialog asking the user).
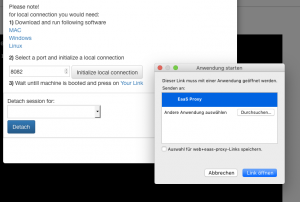
Once the URL handler has been registered, a special URL is provided through the CiTAR landing page to start and connect the local gateway. The user is then able to interact with the archived networked environments, e.g. connecting a current Excel sheet with an archived database server or, in case of the SlaVaComp, interact with the REST interface using local programs or scripts.
CiTAR SlaVaComp Landigpage (local mode) (hdl: 11270/62dddddddd-44ec-4b1d-94b4-887fa139142815)
To be continued…
The CiTAR Team:
Rafael Gieschke, Susanne Mocken, Klaus Rechert, Oleg Stobbe, Oleg Zharkov (University Freiburg), Felix Bartusch (University Tübingen), Kyryll Udod (University Ulm)


December 13, 2018 @ 3:24 pm CET
The correct address should be http://ip:port/exist/apps/metaglossar/
Not sure where you have found the “internal”. The connection info seems to display now the correct url (clickable).Update: we found the problem. Thank you very much for the feedback!
Generalization / normalization is completly automated. An early version is described here: https://openpreservation.org/blog/2017/11/27/getting-started-with-emulation-importing-disk-images/
December 13, 2018 @ 12:16 pm CET
great work & post!
can’t quite the the SlaVaComp to run though .. I get to the eXist dashboard fine but am not sure what settings i’m suppose to take there. Calling up http://ip:port/internal/exist/apps/metaglossar gives an error. For showcasing with DAU’s like myself, it might be worthwhile to have a bit more info on how to & what to expect to bring up SlaVaComp in the CiTAR landing page.
Also, I’m wondering what the process in “generalized/normalized disk images and VMs” is. What steps are taken? Is this automatic and scalable or a manual approach done once when tying the VM into the CiTAR infrastructure?
Looking forward to the other posts of the series!