
Ok. I know what you’re thinking. Do we really need another PRONOM-based, file format identification tool?
A year or so I might have said “no” myself. In DROID and FIDO, we are already blessed with two brilliant tools. In my workplace, we’re very happy users of DROID. We trust it as the reference implementation of PRONOM, it is fast, and it has a rich GUI with useful filtering and reporting options. I know that FIDO has many satisified users too: it is also fast, great for use at the command line, and, as a Python program, is easy to integrate with digital preservation workflows (such as Archivematica). The reason I wrote Siegfried wasn’t to displace either of these tools, it was simply to scratch an itch: when I read the blog posts announcing FIDO a few years ago, I was intrigued at the different matching strategies used (FIDO’s regular expressions and DROID’s Boyer-Moore-Horspool string searching) and wondered what other approaches might be possible. I started Siegfried simply as a hobby project to explore whether a multiple-string search algorithm, Aho Corasick, could perform well at matching signatures.
Having dived down the file format identification rabbit hole, my feeling now is that, the more PRONOM-based, file format identification tools we have, the better. Multiple implementations of PRONOM make PRONOM itself stronger. For one thing, having different algorithms implement the same signatures is a great way of validating those signatures. Siegfried is tested using Ross Spencer’s skeleton suite (a fantastic resource that made developing Siegfried much, much easier). During development of Siegfried, Ross and I were in touch about a number of issues thrown up during that testing, and these issues led to a small number of updates to PRONOM. I imagine the same thing happened for FIDO. Secondly, although many institutions use PRONOM, we all have different needs, and different tools suit different use cases differently. For example, for a really large set of records, with performance the key consideration, your best bet would probably be Nanite (a Hadoop implementation of DROID). For smaller projects, you might favour DROID for its GUI or FIDO for its Archivematica integration. I hope that Siegfried might find a niche too, and it has a few interesting features that I think commend it.
Simple command-line interface
I’ve tried to design Siegfried to be the least intimidating command-line tool possible. You run it with:
sf FILE
sf DIR
There are only two other commands -version and -update (to update your signtures). There aren’t any options: directory recursion is automatic, no default size on search buffers, and output is YAML only. Why YAML? It is a structured format, so you can do interesting things with it, and it has a clean syntax that doesn’t look horrible in a terminal.
Good performance, without buffer limits
I’m one of those DROID users that always sets the buffer size to -1, just in case I miss any matches. The trade-off is that this can make matching a bit slower. I understand the use of buffers limits (options to limit the bytes scanned in a file) in DROID and FIDO – the great majority of signatures are found close to the beginning or end of the file and IO has a big impact on performance – but you need to be careful with them. Buffer limits can confuse users (“I can see a PRONOM signature for PDF/A, why isn’t it matching?”). The use of buffer limits also need to be documented if you want to accurately record how puids were assigned. This is because you are effectively changing the PRONOM signatures by overriding any variable offsets. In other words, you can’t just say, “matched ‘fmt/111’ with DROID signatures v 77”, but now need to say, “matched ‘fmt/111’ with DROID signatures v 77 and with a maximum BOF offset of 32000 and EOF offset of 16000”.
Siegfried is designed so that it doesn’t need buffer limits for good performance. Instead, Siegfried searches as much, or as little, of a file as it needs to in order to satisfy itself that it has obtained the best possible match. Because Siegfried matches signatures concurrently, it can apply PRONOM’s priority rules during the matching process, rather than at the end. The downside of this approach is that while average performance is good, there is variability: Siegfried slows down for files (like PDFs) where it can’t be sure what the best match is until much, or all, of the file has been read.
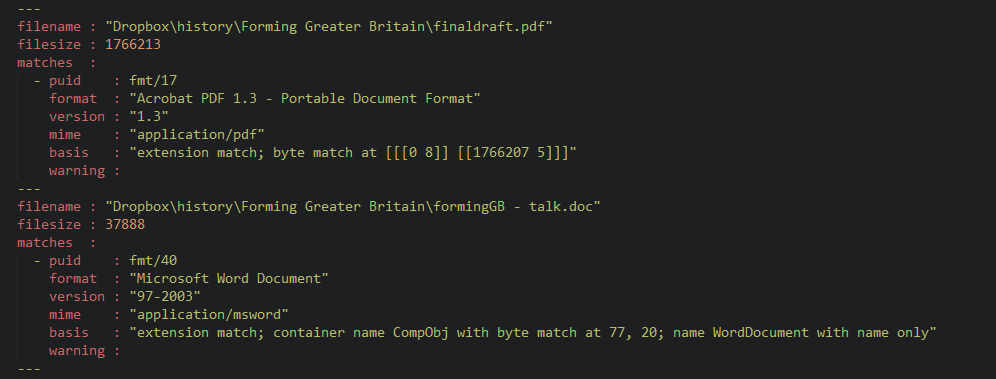
Detailed basis information
As well as telling you what it matched, Siegfried will also report why it matched. Where byte signatures are defined, this “basis” information includes the offset and length of byte matches. While many digital archivists won’t need this level of justification, this information can be useful. It can be a great debugging tool if you are creating new signatures and want to test how they are matching. It might also be useful for going back and re-testing files after PRONOM signature updates: if signatures change and you have an enormous quanitity of files that need to have their puids re-validated, then you could use this offset information to just test the relevant parts of files. Finally, by aggregating this information over time, it may also be possible to use it to refine PRONOM signatures: for example, are all PDF/A’s matching within a set distance from the EOF? Could that variable offset be changed to a fixed one?
Where can I get my hands on it?
You can download Siegfried here. You can also try Siegfried, without downloading it, by dragging files onto the picture of Wagner’s Siegfried on that page. The source is hosted on Github if you prefer to compile it yourself (you just need Go installed). Please report any bugs or feature requests there. It is still in beta (v 0.5.0) and probably won’t get a version one release until early next year. I wouldn’t recommend using it as your only form of file format identification until then (unless you are brave!). But please try it and send feedback.
Finally, I’d like to say thanks very much to the TNA for PRONOM and DROID and to Ross Spencer for his skeleton suite(s).



October 23, 2014 @ 10:10 pm CEST
Excellent, thats really useful, and I can see this being a staple tool in my tool box!
Next question, how easy is it manage the signature space?
I often need to role back to previous sigs, and sometimes make my own… (I've been testing/toying with turning other format signature spaces into PRONON format signature xml, meaning I can use the DROID functionality with my own sigs – this worked well, and something I would like to do more of),
Could I, for example instead of using :-
do this:-
To force my own sigs choices into the engine?
Behaviourally, I would want the default to be the latest sigs, but overrideable as required…
October 23, 2014 @ 9:52 pm CEST
Hi Jay
I think it should be fairly straightforward to do this & have put in a ticket for it (https://github.com/richardlehane/siegfried/issues/17). I don't track the internal signature IDs that DROID uses so I will probably give a relative number instead. I.e. in your PDF/A example then the 1 b 2 signature would be "signature 2 for fmt/354".
Re. the second request (return signature version), this is already there but isn't shown in the (cropped) screen shot. The very first YAML record you get in the output is a provenance block that gives the version of siegfried, the scan date, and a list of all the identifiers used. That list of identifiers will usually just be a single item for PRONOM and it has details about the droid signature version and container signature version. This screen shot: https://twitter.com/richardlehane/status/510712433141223424 shows what that looks like.
cheers
Richard
October 23, 2014 @ 7:49 pm CEST
Hi Richard,
This looks like an interesting and useful tool. Thanks for sharing it.
I wondered if you might consider adding a couple pieces of information to help make it even more useful.
It strikes me that one of things I often want to know is which PRONOM signature triggered a match to a specific PUID. I took a look at PDF/A (1b http://apps.nationalarchives.gov.uk/PRONOM/Format/proFormatSearch.aspx?status=detailReport&id=1100&strPageToDisplay=signatures ) because of Tyler's comments, and realised that to do any work on the signature, I need to know which signature element triggered a match.
I often find myself pulling apart signature elements to try and figure out which is the closest match to a non-matching bitstream, or to see which variant is matching in a multi-variant PUID.
With this in mind, I wondered if you might consider adding a returning piece of data that lists the exact signature pattern that you've matched against.
This would also mean that you can start to capture a record of matches that are meaningful to you, even after the PRONOM signature space has changed (something we see often).
Added to the above, you could make it even more robust by returning the signature version that was used.
I look forward to having a play.
J
October 9, 2014 @ 12:37 am CEST
Thanks Tyler. I'd be careful about saying that siegfried is "more intelligent": It takes a different approach that I think will work well for some use cases but there are trade offs and in many cases DROID or FIDO will be a better choice. Certainly until siegfried is at v1, and has been proven/thoroughly tested, I wouldn't recommend implementing it in a preservation system. But I am very keen on having the community try it and I'd be very grateful for feedback.
In terms of implementating siegfried within systems/workflows, at present siegfried is just command line but I do intend working on a server mode. This would work a bit like the CLAMAV server or a DB server. Benefit of this would be that you could leave siegfried running and just call it from your preservation system on demand, avoiding startup costs (because siegfried uses aho corasick it builds a search tree on startup which does take time). I'm still sketching this out and am very open to suggestions about what form this server should take (HTTP/TCP/streaming/websockets/JSON/XML etc.).
I've been using Trello for planning: https://trello.com/b/ABXkGk6T/siegfried . Very happy for comments there.
October 8, 2014 @ 3:12 pm CEST
We also have been struggling with PDF/A files and their identification. I too am forced to use a buffer size of -1 in order to correctly identify PDF/A files, especially those created with Acrobat 11. Thank you for approaching the problem with a more intelligent tool. Now, how to impletment with our preservation system…