
Ok. I know what you’re thinking. Do we really need another PRONOM-based, file format identification tool?
A year or so I might have said “no” myself. In DROID and FIDO, we are already blessed with two brilliant tools. In my workplace, we’re very happy users of DROID. We trust it as the reference implementation of PRONOM, it is fast, and it has a rich GUI with useful filtering and reporting options. I know that FIDO has many satisified users too: it is also fast, great for use at the command line, and, as a Python program, is easy to integrate with digital preservation workflows (such as Archivematica). The reason I wrote Siegfried wasn’t to displace either of these tools, it was simply to scratch an itch: when I read the blog posts announcing FIDO a few years ago, I was intrigued at the different matching strategies used (FIDO’s regular expressions and DROID’s Boyer-Moore-Horspool string searching) and wondered what other approaches might be possible. I started Siegfried simply as a hobby project to explore whether a multiple-string search algorithm, Aho Corasick, could perform well at matching signatures.
Having dived down the file format identification rabbit hole, my feeling now is that, the more PRONOM-based, file format identification tools we have, the better. Multiple implementations of PRONOM make PRONOM itself stronger. For one thing, having different algorithms implement the same signatures is a great way of validating those signatures. Siegfried is tested using Ross Spencer’s skeleton suite (a fantastic resource that made developing Siegfried much, much easier). During development of Siegfried, Ross and I were in touch about a number of issues thrown up during that testing, and these issues led to a small number of updates to PRONOM. I imagine the same thing happened for FIDO. Secondly, although many institutions use PRONOM, we all have different needs, and different tools suit different use cases differently. For example, for a really large set of records, with performance the key consideration, your best bet would probably be Nanite (a Hadoop implementation of DROID). For smaller projects, you might favour DROID for its GUI or FIDO for its Archivematica integration. I hope that Siegfried might find a niche too, and it has a few interesting features that I think commend it.
Simple command-line interface
I’ve tried to design Siegfried to be the least intimidating command-line tool possible. You run it with:
sf FILE
sf DIR
There are only two other commands -version and -update (to update your signtures). There aren’t any options: directory recursion is automatic, no default size on search buffers, and output is YAML only. Why YAML? It is a structured format, so you can do interesting things with it, and it has a clean syntax that doesn’t look horrible in a terminal.
Good performance, without buffer limits
I’m one of those DROID users that always sets the buffer size to -1, just in case I miss any matches. The trade-off is that this can make matching a bit slower. I understand the use of buffers limits (options to limit the bytes scanned in a file) in DROID and FIDO – the great majority of signatures are found close to the beginning or end of the file and IO has a big impact on performance – but you need to be careful with them. Buffer limits can confuse users (“I can see a PRONOM signature for PDF/A, why isn’t it matching?”). The use of buffer limits also need to be documented if you want to accurately record how puids were assigned. This is because you are effectively changing the PRONOM signatures by overriding any variable offsets. In other words, you can’t just say, “matched ‘fmt/111’ with DROID signatures v 77”, but now need to say, “matched ‘fmt/111’ with DROID signatures v 77 and with a maximum BOF offset of 32000 and EOF offset of 16000”.
Siegfried is designed so that it doesn’t need buffer limits for good performance. Instead, Siegfried searches as much, or as little, of a file as it needs to in order to satisfy itself that it has obtained the best possible match. Because Siegfried matches signatures concurrently, it can apply PRONOM’s priority rules during the matching process, rather than at the end. The downside of this approach is that while average performance is good, there is variability: Siegfried slows down for files (like PDFs) where it can’t be sure what the best match is until much, or all, of the file has been read.
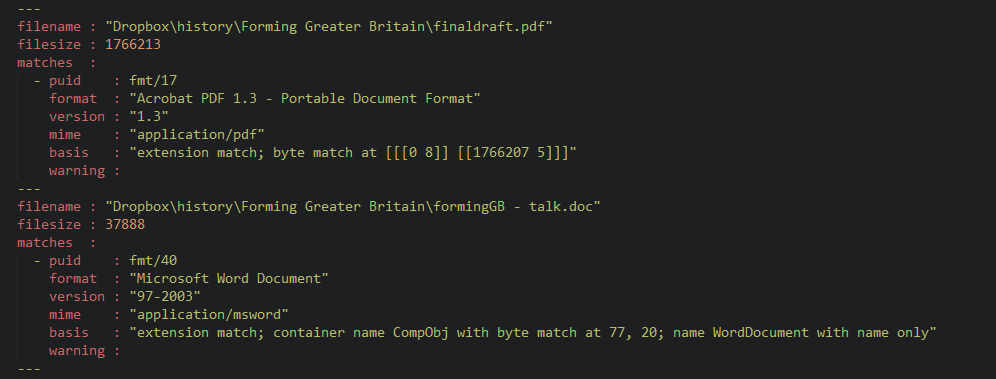
Detailed basis information
As well as telling you what it matched, Siegfried will also report why it matched. Where byte signatures are defined, this “basis” information includes the offset and length of byte matches. While many digital archivists won’t need this level of justification, this information can be useful. It can be a great debugging tool if you are creating new signatures and want to test how they are matching. It might also be useful for going back and re-testing files after PRONOM signature updates: if signatures change and you have an enormous quanitity of files that need to have their puids re-validated, then you could use this offset information to just test the relevant parts of files. Finally, by aggregating this information over time, it may also be possible to use it to refine PRONOM signatures: for example, are all PDF/A’s matching within a set distance from the EOF? Could that variable offset be changed to a fixed one?
Where can I get my hands on it?
You can download Siegfried here. You can also try Siegfried, without downloading it, by dragging files onto the picture of Wagner’s Siegfried on that page. The source is hosted on Github if you prefer to compile it yourself (you just need Go installed). Please report any bugs or feature requests there. It is still in beta (v 0.5.0) and probably won’t get a version one release until early next year. I wouldn’t recommend using it as your only form of file format identification until then (unless you are brave!). But please try it and send feedback.
Finally, I’d like to say thanks very much to the TNA for PRONOM and DROID and to Ross Spencer for his skeleton suite(s).



November 22, 2014 @ 12:46 am CET
Hi Jay
I got the v 0.6.1 release out yesterday (http://www.itforarchivists.com/siegfried). In my earlier comments I’d been talking about r2d2: this tool is now called “roy” and is bundled with the latest release.
I think roy should do those things you asked for. I’ve started a user guide here: https://github.com/richardlehane/siegfried/wiki/Building-a-signature-file-with-ROY.
For rolling back, I’d recommend building a single signature file containing multiple versions of DROID.
You do this with:
roy build -name latest history.gob
roy add -droid DroidSignatureFile_V78.xml -noreports -name v78 history.gob
The second “add” command adds the older signature file to the history.gob file you built with the first command. The name flag allows you to distinguish those identifiers in your results. The noreports flag builds the second signatures purely from the DROID file (doesn’t need PRONOM reports).
In terms of extending with your own signatures, you can do that too.
Do this with:
roy build -extend my-own-sig.xml,my-other-sig.xml
Those additional signature files chould be in DROID xml format and in a “custom” folder in your siegfried home directory.
Hope that all makes sense but happy to help if you run into any trouble.
October 24, 2014 @ 12:35 am CEST
Very nice, I'll have play over the next few days.
This really is an excellent piece of work 🙂
October 24, 2014 @ 12:15 am CEST
there are a bunch of features flagged already (https://github.com/richardlehane/siegfried/issues) that should give you the kind of functionality you want… I think. These are the ones relating to r2d2 development and the ability to set the signature file when running the sf tool.
r2d2 is a separate tool that is used to compile the signature file. I haven’t made it easy to find as yet as it is still rough around the edges but it will get more attention in future releases.
At the moment, you need golang installed and can build it with:
The workflow for getting what you want would then be:
You could then store that file in your collection of classic signatures and at any time run:
In the provenance block you’d get jaysCoolSigs as the identifier and would also see that details text.
Other things you’ll be able to do with r2d2 include setting max BOF and EOF, no containers, no EOF sequences, adding additional non-PRONOM sigs, etc. My feeling is that all this stuff should happen as hard-coded changes to a signature file that you can then keep – and not as command line flags to the sf tool – because it then becomes much easier to track the basis upon which any particular identification was made over time.