
Whenever you run into the situation that you have got used to a command line tool and all of a sudden need to apply it to a large amount of files over a Hadoop cluster without having any clue of writing distributed programs ToMaR will be your friend.
Mathilda is working at the department for digital preservation at a famous national library. In her daily work she has to cope with various well-known tasks like data identification, migration and curation. She is experienced in using the command shell on a Unix system and occasionally has to write small scripts to perform a certain workflow effectively.
When she has got to deal with a few hundreds of files she usually invokes her shell script on one file after the other using a simple loop for automation. But today she has been put in charge of a much bigger data set than she is used to. There are one hundred thousand TIFF images which need to be migrated to JPEG2000 images in order to save storage space. Intuitively she knows that processing these files one after the other with each single migration taking about half a minute would take a whole work day to run.
Luckily Mathilda has heard of the recent Hadoop cluster colleagues of her have set up in order to do some data mining on a large collection of text files. "Would there be a way to run my file migration tool on that cluster thing?", she thinks, "If I could run it in parallel on all these machines then that would speed up my migration task tremendously!" Only one thing makes here hesitate: She has hardly got any Java programming skills, not to mention any idea of that MapReduce programming paradigm they are using in their data mining task. How to let her tool scale?
That's where ToMaR, the Tool-to-MapReduce Wrapper comes in!
What can ToMaR do?
![]() If you have a running Hadoop cluster you are only three little steps away from letting your preservation tools run on thousands of files almost as efficiently as with a native one-purpose Java MapReduce application. ToMaR wraps command line tools into a Hadoop MapReduce job which executes the command on all the worker nodes of the Hadoop cluster in parallel. Dependent on the tool you want to use through ToMaR it might be necessary to install it on each cluster node beforehand. Then all you need to do is:
If you have a running Hadoop cluster you are only three little steps away from letting your preservation tools run on thousands of files almost as efficiently as with a native one-purpose Java MapReduce application. ToMaR wraps command line tools into a Hadoop MapReduce job which executes the command on all the worker nodes of the Hadoop cluster in parallel. Dependent on the tool you want to use through ToMaR it might be necessary to install it on each cluster node beforehand. Then all you need to do is:
- Specify your tool so that ToMaR can understand it using the SCAPE Tool Specification Schema.
- Itemize the parameters of the tool invocation for each of your input files in a control file.
- Run ToMaR.
Through MapReduce your list of parameter descriptions in the control file will be split up and assigned to each node portion by portion. For instance ToMaR could have been configured to create splits of 10 lines each taken from the control file. Then each node parses the portion line by line and invokes the tool with the parameters specified therein each time.
File Format Migration Example
So how may Mathilda tackle her file format migration problem? First she will have to make sure that her tool is installed on each cluster node. Her colleagues who maintain the Hadoop cluster will take care for this requirement. Up to her is the creation of the Tool Specification Document (ToolSpec) using the SCAPE Tool Specification Schema and the itemization of the tool invocation parameter descriptions. The following figure depicts the required workflow:
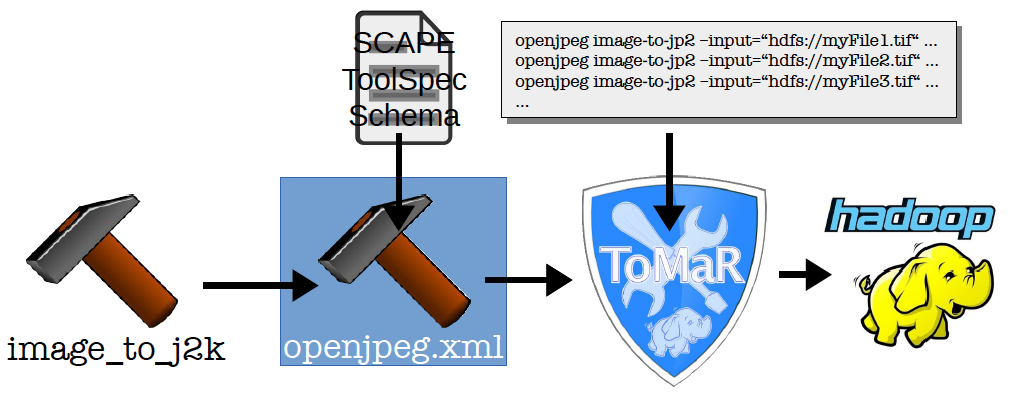
Create the ToolSpec
The ToolSpec is an XML file which contains several operations. An operations consists of name, a description, a command pattern and input/output parameters. The operation for Mathilda's file format migration tool might look like this:
<operation name="image-to-j2k">
<description>Migrates an image to jpeg2000</description>
<command>
image_to_j2k -i ${input} -o ${output} -I -p RPCL -n 7 -c [256,256],
[256,256],[128,128],[128,128],[128,128],[128,128],[128,128] -b 64,64
-r 320.000,160.000,80.000,40.000,20.000,11.250,7.000,4.600,3.400,2.750,
2.400,1.000
</command>
<inputs>
<input name="input" required="true">
<description>Reference to input file</description>
</input>
</inputs>
<outputs>
<output name="output" required="true">
<description>Reference to output file. Only *.j2k, *.j2c or *.jp2!</description>
</output>
</outputs>
</operation>
In the <command> element she has put the actual command line with a long tail of static parameters. This example highlights another advantage of the ToolSpec: You gain the ease of wrapping complex command lines in an atomic operation definition which is associated with a simple name, here "image-to-j2k". Inside the command pattern she puts placeholders which are replaced by various values. Here ${input} and ${output} denote such variables so that the value of the input file parameter (-i) and the value of the output file parameter (-o) can vary with each invocation of the tool.
Along with the command definition Mathilda has to describe these variables in the <inputs> and <outputs> section. For the ${input} being the placeholder for a input file she has to add a <input> element with the name of the placeholder as an attribute. The same counts for the ${output} placeholder. Additionally she can add some description text to these input and output parameter definitions.
There are more constructs possible with the SCAPE Tool Specification Schema which can not be covered here. The full contents of this ToolSpec can be found in the file attachments.
Create the Control File
The other essential requirement Mathilda has to achieve is the creation of the control file. This file contains the real values for the tool invocation which are mapped to the ToolSpec by ToMaR. Together with the above example her control file will look something like this:
openjpeg image-to-jp2 --input=“hdfs://myFile1.tif“ --output=“hdfs://myFile2.jp2“ openjpeg image-to-jp2 --input=“hdfs://myFile2.tif“ --output=“hdfs://myFile2.jp2“ openjpeg image-to-jp2 --input=“hdfs://myFile3.tif“ --output=“hdfs://myFile3.jp2“ ...
The first word refers to the name of the ToolSpec ToMaR shall load. In this example the ToolSpec is called "openjpeg.xml" but only the name without the .xml extension is needed for the reference. The second word refers to an operation within that ToolSpec, it's the "image-to-j2k" operation described in the ToolSpec example snippet above.
The rest of the line contains references to input and output parameters. Each reference starts with a double dash followed by a pair of parameters name and value. So –input (and likewise –output) refers to the parameters named "input" in the ToolSpec which in turn refers to the ${input} placeholder in the command pattern. The values are file references on Hadoop's Distributed File System (HDFS).
As Mathilda has 100k TIFF images she will have 100k lines in her control file. As she knows how to use the command shell she quickly writes a script which generates this file for her.
Run ToMaR
Having the ToolSpec openjpeg.xml and the control file controlfile.txt created she copies openjpeg.xml into the directory "hdfs:///user/mathilda/toolspecs" of HDFS and executes the following command on the master node of the Hadoop cluster:
hadoop jar ToMaR.jar -i controlfile.txt -r hdfs:///user/mathilda/toolspecs
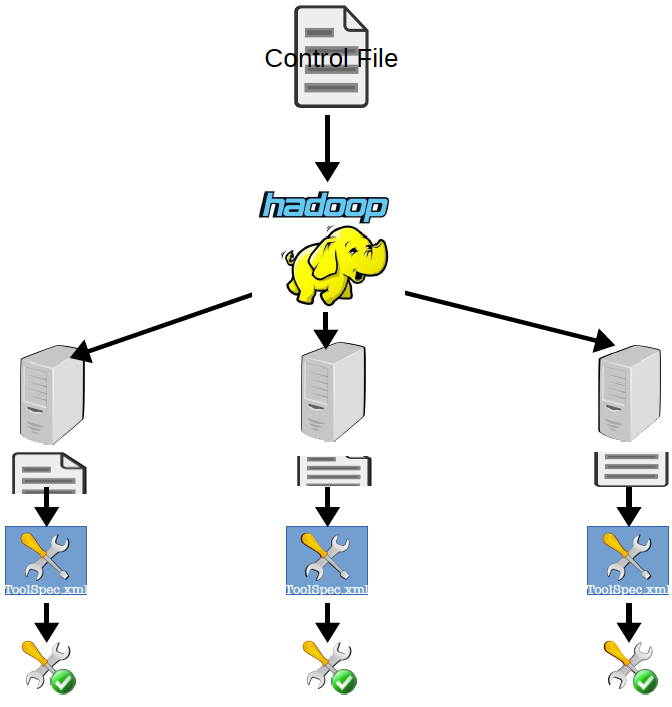 Here she feeds in the controlfile.txt and the location of her ToolSpecs and ToMaR does the rest. It splits up the control file and distributes a certain number of lines per split to each node. The ToolSpec is loaded and the parameters are mapped to the command line pattern contained in the named operation. Input files are copied from HDFS to the local file system. As the placeholders are replaced by the values the command line can be executed by the worker node. After that the result output file is copied back to HDFS to the output location given.
Here she feeds in the controlfile.txt and the location of her ToolSpecs and ToMaR does the rest. It splits up the control file and distributes a certain number of lines per split to each node. The ToolSpec is loaded and the parameters are mapped to the command line pattern contained in the named operation. Input files are copied from HDFS to the local file system. As the placeholders are replaced by the values the command line can be executed by the worker node. After that the result output file is copied back to HDFS to the output location given.
Finally Mathilda has got all the migrated JPEG2000 images on HDFS in a fraction of the time it would have taken when run sequentially on her machine.
Benefits
- easily take up external tools with a clear mapping between the instructions and the physical invocation of the tool
- use the SCAPE Toolspec, as well as existing Toolspecs, and its advantage of associating simple keywords with complex command-line patterns
- no programming skills needed as the minimum requirement only is to setup the control file
Summary
When dealing with large volumes of files, e.g. in the context of file format migration or characterisation tasks, a standalone server often cannot provide sufficient throughput to process the data in a feasible period of time. ToMaR provides a simple and flexible solution to run preservation tools on a Hadoop MapReduce cluster in a scalable fashion.
ToMaR offers the possibility to use existing command-line tools in Hadoop's distributed environment very similarly to a desktop computer. By utilizing SCAPE Tool Specification documents, ToMaR allows users to associate complex command-line patterns with simple keywords, which can be referenced for execution on a computer cluster. ToMaR is a generic MapReduce application which does not require any programming skills.
Checkout the following blog posts for further usage scenarios of ToMaR:
- http://www.openpreservation.org/blogs/2013-12-16-web-archive-fits-characterisation-using-tomart
- http://www.openpreservation.org/blogs/2014-03-07-some-reflections-scalable-arc-warc-migration
And where can I find the software?
Checkout the github repository: https://github.com/openplanets/ToMaR


