
It is well-known that PDF documents can contain features that are preservation risks (e.g. see here and here). Migration of existing PDFs to PDF/A is sometimes advocated as a strategy for mitigating these risks. However, the benefits of this approach are often questionable, and the migration process can also be quite risky in itself. As I often get questions on this subject, I thought it might be worthwhile to do a short write-up on this.
PDF/A is a profile
First, it's important to stress that each of the PDF/A standards (A-1, A-2 and A-3) are really just profiles within the PDF format. More specifically, PDF/A-1 offers a subset of PDF 1.4, whereas PDF/A-2 and PDF/A-3 are based on the ISO 32000 version of PDF 1.7. What these profiles have in common, is that they prohibit some features (e.g. multimedia, encryption, interactive content) that are allowed in 'regular' PDF. Also, they narrow down the way other features are implemented, for example by requiring that all fonts are embedded in the document. This can be illustrated with the following simple Venn diagram below, which shows the feature sets of the aforementioned PDF flavours:
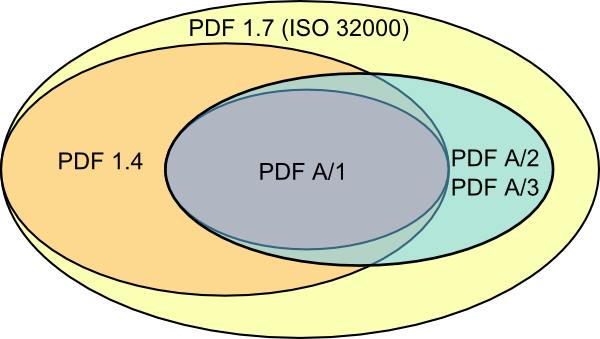
Here we see how PDF/A-1 is a subset of PDF 1.4, which in turn is a subset of PDF 1.7. PDF A/2 and PDF A/3 (aggregated here as one entity for the sake of readability) are subsets of PDF 1.7, and include all the features of PDF A/1.
Keeping this in mind, it's easy to see that migrating an arbitrary PDF to PDF/A can result in problems.
Loss, alteration during migration
Suppose, as an example, that we have a PDF that contains a movie. This is prohibited in PDF/A, so migrating to PDF/A will simply result in the loss of the multimedia content. Another example are fonts: all fonts in a PDF/A document must be embedded. But what happens if the source PDF uses non-embedded fonts that are not available on the machine on which the migration is run? Will the migration tool exit with a warning, or will it silently use some alternative, perhaps similar font? And how do you check for this?
Complexity and effect of errors
Also, migrations like these typically involve a complete re-processing of the PDF's internal structure. The format's complexity implies that there's a lot of potential for things to go wrong in this process. This is particularly true if the source PDF contains subtle errors, in which case the risk of losing information is very real (even though the original document may be perfectly readable in a viewer). Since we don't really have any tools for detecting such errors (i.e. a sufficiently reliable PDF validator), these cases can be difficult to deal with. Some further considerations can be found here (the context there is slightly different, but the risks are similar).
Digitised vs born-digital
The origin of the source PDFs may be another thing to take into account. If PDFs were originally created as part of a digitisation project (e.g. scanned books), the PDF is usually little more than a wrapper around a bunch of images, perhaps augmented by an OCR layer. Migrating such PDFs to PDF/A is pretty straightforward, since the source files are unlikely to contain any features that are not allowed in PDF/A. At the same time, this also means that the benefits of migrating such files to PDF/A are pretty limited, since the source PDFs weren't problematic to begin with!
The potential benefits PDF/A may be more obvious for a lot of born-digital content; however, for the reasons listed in the previous section, the migration is more complex, and there's just a lot more that can go wrong (see also here for some additional considerations).
Conclusions
Although migrating PDF documents to PDF/A may look superficially attractive, it is actually quite risky in practice, and it may easily result in unintentional data loss. Moreover, the risks increase with the number of preservation-unfriendly features, meaning that the migration is most likely to be successful for source PDFs that weren't problematic to begin with, which belies the very purpose of migrating to PDF/A. For specific cases, migration to PDF/A may still be a sensible approach, but the expected benefits should be weighed carefully against the risks. In the absence of stable, generally accepted tools for assessing the quality of PDFs (both source and destination!), it would also seem prudent to always keep the originals.

August 29, 2014 @ 2:45 pm CEST
As to your last point/question Will, Acrobat running on Windows XP in a browser is already here:
We are running a local installation of the bw-FLA Emulation as a Service (EaaS) software framework here at Yale Library (more info on our use of it is available here.) It took me longer to sort out that screenshot than it did to boot that machine in the browser.
Edit: The data detailing the types of files that were tested in that research is available here.
August 29, 2014 @ 1:56 pm CEST
I don't know what sort of objects those were but this is where emulation could well be a better solution, with fewer errors/risks and at a lower overall cost.
i.e. no need to convert Lotus 123 files as they can be opened in the original software in DOSBox (host architecture independent), or hosting an environment like Linux in a browser: http://bellard.org/jslinux/, or migration/emulation-on-access like this: http://www.webarchive.org.uk/interject/, or back to the original subject, one day having Windows XP with Acrobat running in a browser (it can't be far off!)
August 29, 2014 @ 1:37 pm CEST
I agree with you both that more evidence would be great. Unfortunately it is quite costly to collect.
In the research I led while at Archives NZ I found that testing whether content was still being presented when files were opened in software environments that differed from a 'control' (original) environment, it took (on average) 9 minutes to review the content of a single file. To get a reasonable set of data on the effects of migration, if manual testing is to be done, will likely take a similarly long time, and therefore be quite costly.
It does need to be done though!
e.g:
August 29, 2014 @ 9:03 am CEST
Hi Ross,
I thought the blog was a good overview of the issues (from someone who has looked into the issues a lot) and didn't pretend to be anything other than that. If the blog post sparks fears then that is probably a good thing! It means that whoever has that fear hadn't done their research before a migration.
I appreciate your call for evidence; it would be great to see the results of a large-scale audit of features contained in PDF files. Some initial work we did is here: http://wiki.opf-labs.org/display/SP/EVAL-BL-LSDRT-PDFDRM-01 (scroll down a bit)
Surely, the point is that migration, just for the sake of migration, is not necessarily a good idea and can be risky. Converting from PDF to PDF/A does seem to get mentioned from time to time and if this blog prompts people to think about that some more, and do their own research then it is a good thing.
I would argue that (not) embedded fonts alone is not a good reason for a migraiton – if you want to include them in a PDF/A then you must have them. So just keep the fonts, archive them too, and avoid a risky migration.
The community as a whole needs to come up with proofs and that is the sort of thing I think we should be doing more of. Starting with a hypothesis is no bad idea
Regards,
Will
August 29, 2014 @ 8:34 am CEST