
Authors: Martin Schaller, Sven Schlarb, and Kristin Dill
In the SCAPE Project, the memory institutions are working on practical application scenarios for the tools and solutions developed within the project. One of these application scenarios is the migration of a large image collection from one format to another.
There are many reasons why such a scenario may be of relevance in a digital library. On the one hand, conversion from an uncompressed to a compressed file format can significantly decrease storage costs. On the other hand, particularly from a long-term perspective, file formats may be in danger of becoming obsolete, which means that institutions must be able to undo the conversion and return to the original file format. In this case a quality assured process is essential to allow for reconstruction of the original file instances and especially to determine when deletion of original uncompressed files is needed – this is the only way to realize the advantage of reducing storage costs. Based on these assumptions we have developed the following use case: Uncompressed TIFF image files are converted into compressed JPEG2000 files; the quality of the converted file is assured by applying a pixel for pixel comparison between the original and the converted image.
For this, a sequential Taverna concept workflow was first developed, which was then modelled into a scalable procedure using different tools developed in the SCAPE Project.
The Taverna Concept Workflow
The workflow input is a text file containing paths to the TIFF files to be converted. This text file is then transformed into a list that allows the sequential conversion of each file, hence simulating a non-scalable process. Before the actual migration commences, validity of the TIFF file is checked. This step is realized by using FITS – a wrapper that applies different tools to extract the identification information of a file. Since the output of FITS is an XML-based validation report, an XPath service extracts and checks the validity information. If the file is valid, migration from TIFF to JPEG2000 can begin. The tool used in this step is OpenJPEG 2.0. In order to verify the output, Jpylyzer – a validator as well as feature extractor for JPEG2000 images created within the SCAPE Project – is employed. Again, an Xpath service is used to extract the validity information. This step concludes the file format conversion itself, but in order to ensure that the migrated file is indeed a valid surrogate, the file is reconverted into a TIFF file, again using OpenJPEG 2.0. Finally, in a last step the reconverted and the original TIFF files are compared pixel for pixel using LINUX based ImageMagick. Only through the successful execution of this final step can the validity as well as the possibility of a complete reconversion be assured. 
Figure 1 (above): Taverna concept workflow
In order to identify how much time was consumed by each element of this workflow, we ran a test consisting of the migration of 1,000 files. Executing the described workflow on the 1,000 image files took about 13 hours and five minutes. Rather unsurprisingly, conversion and reconversion of the files took the longest: the conversion to JPEG2000 took 313 minutes and the reconversion 322 minutes. FITS validation needed 70 minutes and the pixel-wise comparison was finished in 62 minutes. The SCAPE developed tool Jypylizer required only 18 minutes and was thus much faster than the above mentioned steps. 
Figure 2 (above): execution times of each of the concept workflows' steps
Making the Workflow Scale
The foundation for the scalability of the described use case is a Hadoop cluster containing five Data Nodes and one Name Node (specification: see below). Besides having economic advantages – Hadoop runs on commodity hardware – it also bears the advantage of being designed for failure, hence reducing the problems associated with hardware crashes.
The distribution of tasks for each core is implemented via MapReduce jobs. A Map job splits the handling of a file. For example, if a large text file is to be processed, a Map job divides the file into several parts. Each part is then processed on a different node. Hadoop Reduce jobs then aggregates the outputs of the processing nodes again to a single file.
But writing MapReduce jobs is a complex matter. For this reason, the programming language Apache Pig is used. Pig was built for Hadoop and translates a set of commands in a language called “Pig Latin” into MapReduce jobs, thus making the handling of MapReduce jobs much easier or, as Professor Jimmy Lin described the powerful tool during the ‘Hadoop-driven digital preservation Hackathon’ in Vienna, easy enough “… for lazy pigs aiming for hassle-free MapReduce.”
Hadoop HDFS, Hadoop MapReduce and Apache Pig make up the foundation of the scalability on which the SCAPE tools ToMaR and XPath Service are based. ToMaR wraps command line tasks for parallel execution as Hadoop MapReduce jobs. These are in our case the execution of FITS, OpenJPEG 2.0, Jpylyzer and ImageMagick. As a result, the simultaneous execution of these tools on several nodes is possible. This has a great impact on execution times as Figure 3 (below) shows.
The blue line represents the non-scalable Taverna workflow. It is clearly observable how the time needed for file migration increases in proportion to the number of files that are converted. The scalable workflow, represented by the red line, shows a much smaller increase in time needed, thus suggesting that scalability has been achieved. This means that, by choosing the appropriate size for the cluster, it is possible to migrate a certain number of image files within a given time frame. 
Figure 3 (above): Wallclock times of concept workflow and scalable workflow
Below is the the specification of the Hadoop Cluster where the master node runs the jobtracker and namenode/secondary namenode daemons, and the worker nodes each runs a tasktracker and a data node daemon.
Master node: Dell Poweredge R510
- CPU: 2 x Xeon [email protected]
- Quadcore CPU (16 HyperThreading cores)
- RAM: 24GB
- NIC: 2 x GBit Ethernet (1 used)
- DISK: 3 x 1TB DISKs; configured as RAID5 (redundancy); 2TB effective disk space
Worker nodes: Dell Poweredge R310
- CPU: 1 x Xeon [email protected]
- Quadcore CPU (8 HyperThreading cores)
- RAM: 16GB
- NIC: 2 x GBit Ethernet (1 used)
- DISK: 2 x 1TB DISKs; configured as RAID0 (performance); 2TB effective disk space
However, the throughput we can reach using this cluster and pig/hadoop job configuration is limited; as figure 4 shows, the throughput (measured in Gigabytes per hour – GB/h) is rapidly growing when the number of files being processed is increased, and then stabilises at a value around slightly more than 90 Gigabytes per hour (GB/h) when processing more than 750 image files. 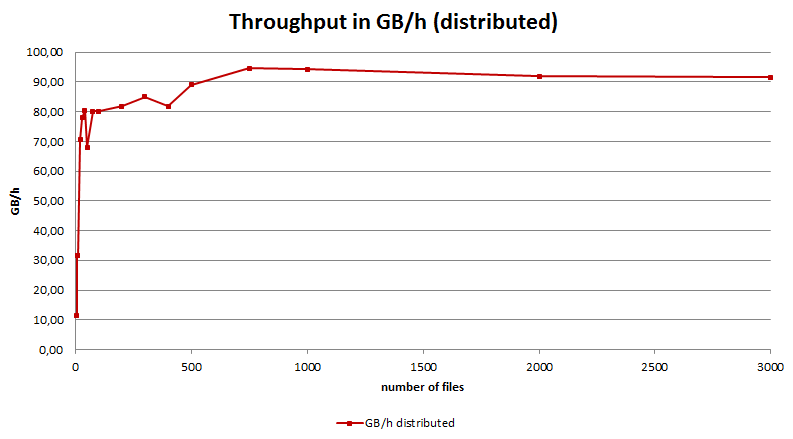
Figure 4 (above): Throughput of the distributed execution measured in Gigabytes per hour (GB/h) against the number of files processed
As our use case shows, by using a variety of tools developed in the SCAPE Project together with the Hadoop framework it is possible to distribute the processing on various machines thus enabling the scalability of large scale image migration and significantly reducing the time needed for data processing. In addition, the size of the cluster can be tailored to fit the size of the job so that it can be completed within a given time frame.
Apart from the authors of this blog post, the following SCAPE Project partners contributed to this experiment:
- Alan Akbik, Technical University of Berlin
- Matthias Rella, Austrian Institute of Technology
- Rainer Schmidt, Austrian Institute of Technology
