
The Scape Characterisation Tool Testing Suite
This information have also been published in the Scape Deliverable D9.1.
We have created a testing framework based on the Govdocs1 digital Corpora (http://digitalcorpora.org/corpora/files), and are using the characterisation results from Forensic Innovations, Inc. ((http://www.forensicinnovations.com/), as ground truths.
The framework we used for this evaluation can be found on
https://github.com/openplanetsfoundation/Scape-Tool-Tester
All the tested tools use a different identification scheme for formats of files. As a common denominator, we have decided to use Mime Types. Mimetypes are not detailed enough to contain all the relevant information about a file format, but all the tested tools are capable of reducing their more complete results to mimetypes. This thus ensures a level playing field.
The ground truths and the corpus
The govdocs1 corpus is a set of about 1 million files, freely available (http://digitalcorpora.org/corpora/files). Forensic Innovations, Inc. (http://www.forensicinnovations.com/) have kindly provided the ground truths for this testing framework, in the form of http://digitalcorpora.org/corp/files/govdocs1/groundtruth-fitools.zip. Unfortunately, they do not list mimetypes for each file, but rather a numeric ID, which seems to be vendor specific. They do provide this mapping, however, http://www.forensicinnovations.com/formats-mime.html, which allows us to match IDs to mimetypes. The list is not complete, as they have not provided mimetypes for certain formats (which they claim do not have mimetypes). For the testing suite, we have chosen to disregard files that Forensic Innovations, Inc. do not provide mimetypes for, as they make up a very small part of the collection. The remaining files number 977885.
The reduced govdocs1 corpus contains files of 87 different formats. These are not evenly distributed, however. Some formats are only represented by a single file, while others make up close to 25% of the corpus.
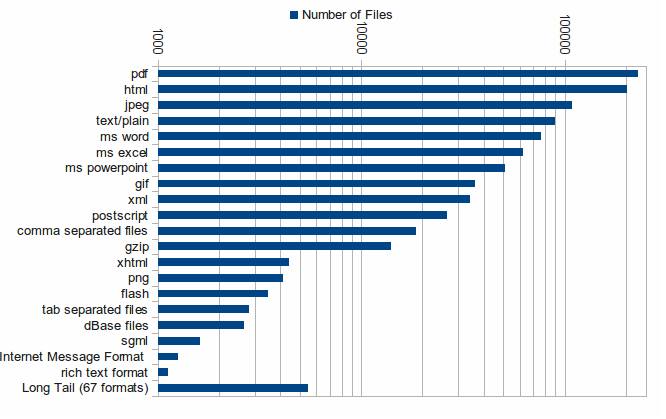
To display the results, we have chosen to focus on the 20 most common file formats in the corpus, and to list the remainding 67 as the long tail, as these only make up 0.56% of the total number of files in the corpus.
One interesting characteristic of the ID-to-mime table from Forensic Innovations, Inc. is that each format only have one mimetype. Now, in the real world, this is patently untrue. Many formats have several mimetypes, the best known example probably being text/xml and application/xml. To solve this problem, we have introduced the mimetype-equivalent list, which ammends the ground truths with additional mimetypes for certain formats. It should be noted that this list have been constructed by hand, simply by looking at the result of the characterisation tools. Any result that do not match the ground truth is recorded as an error, but inspection of the logs later have allowed us to pick up the results that should not have been errors, but rather alias results.
The test iterator
We have endeavoured to use the tools in a production-like way for benchmarking purposes. This means that we have attempted to use the tools’ own built-in recursion features, to avoid redundant program startups (most relevant for the java based tools). Likewise, we have, if possible, disabled those parts of the tools, that are not needed for format identification (most relevant for Tika). We have hidden the filenames from the tools (by simple renaming the data files), in order to test their format identification capabilities, without recursion to file extension.
Versions
Tika: 1.0 release
Droid: 6.0 release, Signature version 45
Fido: 0.9.6 release
Tika – a special note
For this test, Tika have been used as a java library, and have been wrapped in a specialised Java program (https://github.com/blekinge/Tika-identification-Wrapper). This way, we can ensure that only the relevant parts of Tika is being invoked (ie. identification) and not the considerably slower metadata extraction parts. By letting java, rather than the test framework handle the iteration over the files in the archve, we have also been able to measure the performance in a real massprocessing situation, rather than the large overhead in starting the JVM for each file.
Results
We have tested how precisely the tools have been able to produce results to match the ground truths. As stated, we have focused on the 20 most common formats in the corpus, and bundled the remainder into a bar called the Long Tail.
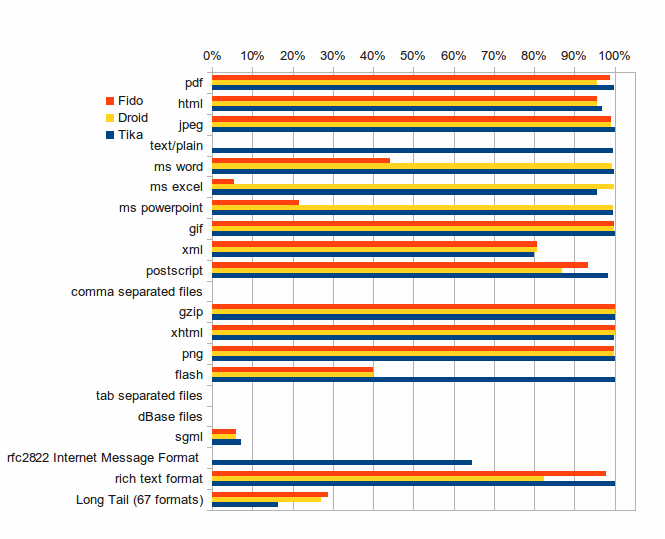
As can be seen from this graph, Tika generally performs best for all the 20 most common formats. Especially for text files (text/plain), it is the only tested tool that correctly identifies the files. For office files, especially excel and powerpoint, droid seems to be more precise. Tika is almost as precise, but Fido loses greatly here. Given that Fido is based on the Droid signatures, it might be surprising why it seems to outperform Droid for certain formats, but this is clear for pdf, postscript and rich text format. The authors will not speculate on why this is so.
Comma/tab separated files are fairly common in the corpus. Tika cannot detect this feature of the files, and recognize them as text/plain files. Fido and Droid fails to identify the files, just as they do for text/plain files.
The dBase files, a somewhat important feature of the corpus is not detected by any of the tools.
Only Tika identifies any files as rfc2822, and even then it misses a lot. All three tools are equally bad at identifing sgml files.
Interestingly, Droid and Fido seems to work much better than Fido on the long tail of formats.
The Long tail
We feel that the long tail of formats is worth looking more closely at.
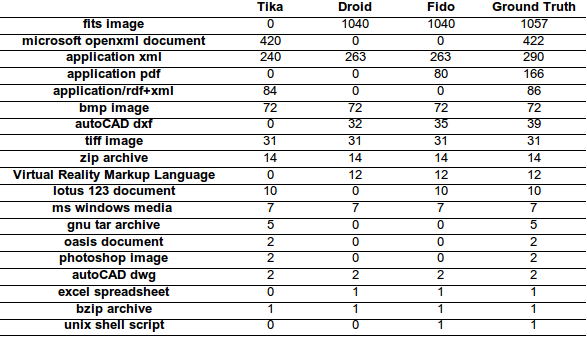
In this table, we have removed any format where none of the tools managed to identify any files. So, this table is to show the different coverage of the tools. We see that it is not just different levels of precision that matter, but which formats are supported by which tools.
Droid and fido support the Fits image format. Tika does not. Tika however, supports the openxml document format, which Fido and Droid does not.
Application pdf and application xml are some rather odd files (otherwise the ground truths would have marked them as normal pdfs or xmls). Here Tika is worse than the other tools. Tika, however, is able to recognize RDF, as shown by the application/rdf+xml format.
It is clear that while the overall precision in the long tail is almost equivalent for the three tools, the coverage differs greatly. If Tika, for example, gained support for the fits image format, it would outperform Droid and Fido on the long tail. Droid and Fido, however, would score much higher, if they gained Tikas support for Microsoft openxml documents.
The speed of the tools
For production use of these tools, not just the precision, but also the performance of the tools are critical. For each tool, we timed the execution, to show us the absolute time, in which the tool is able to parse the archive. Of course, getting precise numbers here is difficult, as keeping an execution totally free of delays is almost impossible on modern computer systems.
We ran each of the tools on a dell poweredge m160 blade server, with two Intel(R) Xeon(R) CPU X5670 @ 2.93GHz. The server had 70 GB RAM, in the form of 1333MHz Dual Ranked LV RDIMMs.
The corpus was mounted on file server accessed through a mounted Network File System via Gigabit network interface.
Each of the tools were allowed to run as the only significant process on the given machine, but we could not ensure that no delayes were caused by the network, as this was shared with other processes in the organisation.
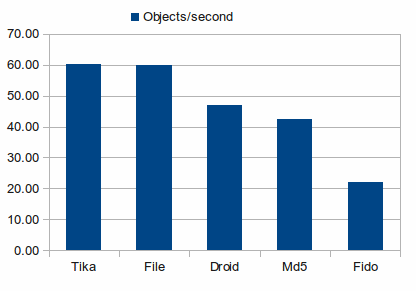
To establish baselines, we have added two additional ”tools”, the unix File tool and the md5 tool.
The Unix File tool check the file headers against a database of signatures. Being significantly faster than the File tool indicates that the tool was able to identify the file without reading the contents. To do so, it would probably have to rely on filenames. Tika seems to be faster, but such small differences are covered by the uncertainties in the system.
Md5 is not a characterisation tool. Rather, it is a checksumming tool. To checksum a file, the tool needs to read the entire file. For the system in question the actual checksum calculation in neglible, so Md5 gives a baseline for reading the entire archive.
As can be seen, Tika is the fastests of the tools, and Fido is the slowest. That the showdown was to be between Tika and Droid was expected. Python does not have a Just In Time compiler, and will not be able to compete with java for such long running processes. That Fido was even slower than Md5 came as a surprise, but again, Md5 is written in very optimised C, and Fido is still python.


July 13, 2012 @ 7:13 pm CEST
The ground truths for the Corpora were generated with our FI TOOLS (http://www.forensicinnovations.com/fitools.html) product. You’re welcome to download a trial version to test yourself. We provide the MIME types for the file types that we have been able to find a reference for. Some people make up MIME types for files, but if they aren’t registered or widely used, then they are worthless. For any file type that we do not provide a MIME type for, you can use the x-??? nomenclature to create your own non-registered MIME as is acceptable to the registering authority. You should find multiple MIME types for some of the file types on the web page referenced in this article. I’m not sure why the writer stated otherwise.
We provided the ground truths at the request of the Corpora creator, in order to help make the Corpora more useful and easy to reference. The core technology powering FI TOOLS is being used by some of the most respected eDiscovery service providers, and has been fine tuned over the past 17 years. We typically only provide a single ID value for each file type, unless there are known compatibility issues between specific format versions. We also provide file format version numbers in the metadata output of many of the file types.
I would have liked to see FI TOOLS included in these tests. At least in the speed test. I expect that it would have completed the task at 60 files/s to 120 files/s on that hardware platform. I assume the reason for leaving it out is due to the lack of a Linux version (other than the sample application included in the API kit), or the fact that we sell the product in order to support further development rather than give it away as open source. It would be interesting to see this test run again with FI TOOLS, Oracle’s Outside-In FileID and TrID. Then it would be more useful to developers looking for the best solution rather than just the fastest free solution.
March 29, 2012 @ 1:49 am CEST
I wondered if you’ve done any analysis on the reason for the varied performance of the tools? Is it an issue with the tool or an issue with the sets of objects?
How strong is the ground truth for this set, and what level of granularity does that ground truth suppport (i.e. this is a jpg, or this is a jpeg version X, or this is a jpeg version X with profile variables ABC etc)?
March 5, 2012 @ 12:31 pm CET
Hi Asgar,
It would be very nice if you could re-run the test with FIDO v1, which offers support for container files.
On a sidenote: is the Scape Deliverable D9.1 you refer to already somewhere to be found online?
IMHO it is necessary to streamline these kind of tests. Most ideal, we would need to evaluate what we want to measure and how we want to measure this. With this I don’t mean the identification results (in this particular case) but aspects such as:
We need to have this information, not only to make it possible to compare tests in a more honest way, but also to re-run the test. This could be applicable when, for example, a new version of a tested application is available.
March 3, 2012 @ 3:31 pm CET
Just to be clear, I should note that DROID identifies a much larger range of particular versions of formats than any other tool currently available. However, these tests are focussed on coverage rather than fine-grained identification because we are trying to cope with the range of formats present in diverse collections like web archives.