
Today, the UK Web Archive is releasing a new suite of visualisations and datasets. Amongst these is a dataset that I imagine will be of interest to this audience, as it concerns format identification and tools. I will be presenting the full results at iPres 2012, but I wanted to give you a sneak preview, and encourage you all to take a look at the associated dataset.
Working with JISC, the UK Web Archive has obtained a copy of all the web resources in the Internet Archive that are from the .uk domain, or embedded within .uk web pages. This contains some 2.5 billion HTTP 200 responses stretching from 1996 to 2010, neatly packed into ARC files and stored on our HDFS cluster. And seeing as it’s HDFS, this means we can run Map-Reduce tasks over the whole dataset, and analyse the results.
Given this infrastructure, my first thought was to use it to test and compare format identification processes by running multiple identification tools over the same corpus. By analysing the depth and coverage of the results, we can estimate which tools are better suited to which types of resources and collection. Furthermore, much as double re-keying can be used to establish ‘groud truth’ for OCR data, each tool acts as an independent opinion on the format of an resource and so permits us a little more confidence in their assertions when they are found to coincide. This allows us to focus our attention on where the tools disagree, and helps to ensure that our efforts to improve those tools will have the greatest impact.
To this end, I wrapped up Apache Tika and the DROID binary signature identifier as part of a Map-Reduce task and ran them over the entire corpus. I mapped the results of both to a formalised extended MIME type syntax, such that each PUID has a unique MIME type of the form ‘application/pdf; version=1.4’, and used that to compare the results of the tools.
Of course, as well as establishing trust in the tools, this kind of data helps us start to explore the way format usage has changed over time, and is a necessary first step in understanding the nature of format obsolescence. As a taster, here is a chart showing the usage ofdifferent version of HTML over time:
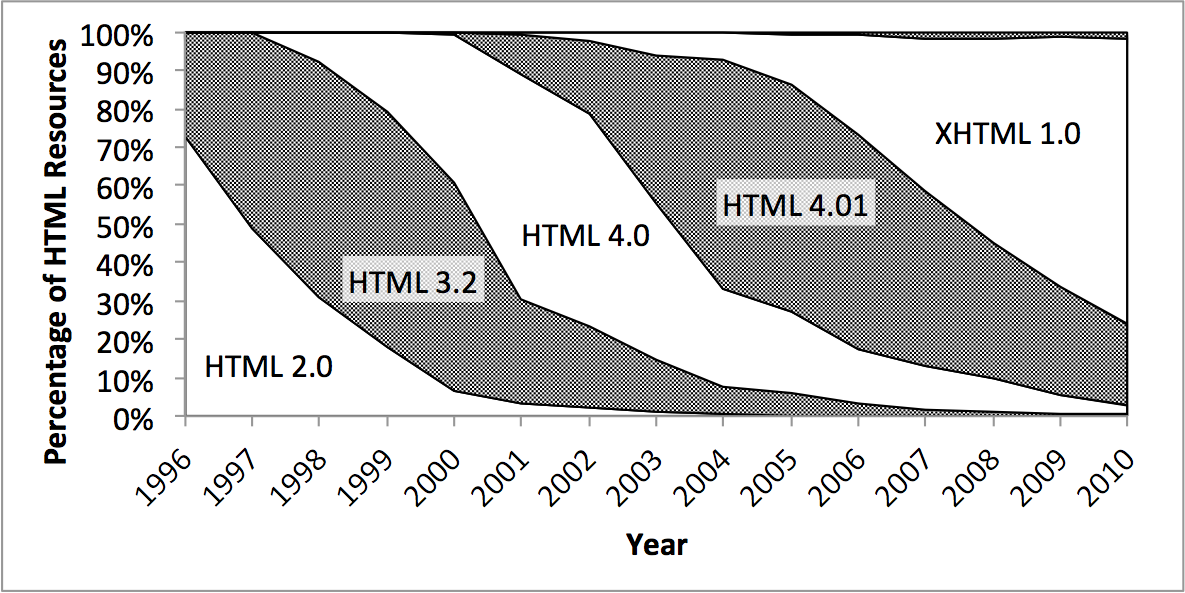
As you can see, each version rises to dominance and then fades away, but the fade slows down each time. Across the 2010 timeslice, all the old versions of HTML are still turing up in the crawl. You can find some more information and results on the UK Web Archive site.
Finally, as well as exporting the format identifiers, I also used Apache Tika to extract any information it found about the software or hardware platform the resource was created on. All of this information was combined with the MIME type declared by the server and then aggregated by year to produce a rich and complex longtitudinal multi-tool format profile for this collection.
If this is of interest to you, please go and download the dataset and start exploring it. I’ve only got so much time to spend analysing the results, and while I’ll share whatever I can, there’s only so much I can do without your help. Please let me know if you find this dataset useful, and please share any interesting results you dig out of the dataset.

