
This blog follows up on three earlier posts about detecting preservation risks in PDF files. In part 1 I explored to what extent the Preflight component of the Apache PDFBox library can be used to detect specific preservation risks in PDF documents. This was followed up by some work during the SPRUCE Hackathon in Leeds, which is covered by this blog post by Peter Cliff. Then last summer I did a series of additional tests using files from the Adobe Acrobat Engineering website. The main outcome of this more recent work was that, although showing great promise, Preflight was struggling with many more complex PDFs. Fast-forward another six months and, thanks to the excellent response of the Preflight developers to our bug reports, the most serious of these problems are now largely solved1. So, time to move on to the next step!
Govdocs Selected
Ultimately, the aim of this work is to be able to profile large PDF collections for specific preservation risks, or to verify that a PDF conforms to an institute-specific policy before ingest. To get a better idea of how that might work in practice, I decided to do some tests with the Govdocs Selected dataset, which is a subset of the Govdocs1 corpus. As a first step I ran the latest version of Preflight on every PDF in the corpus (about 15 thousand)2.
Validation errors
As I was curious about the most common validation errors (or, more correctly, violations of the PDF/A-1b profile), I ran a little post-processing script on the output files to calculate error occurrences. The following table lists the results. For each Preflight error (which is represented as an error code), the table shows the number of PDFs for which the error was reported (expressed as a percentage)3.
| Error code | % PDFs reported | Description (from Preflight source code) |
|---|---|---|
| 2.4.3 | 79.5 | color space used in the PDF file but the DestOutputProfile is missing |
| 7.1 | 52.5 | Invalid metadata found |
| 2.4.1 | 39.1 | RGB color space used in the PDF file but the DestOutputProfile isn't RGB |
| 1.2.1 | 38.8 | Error on the object delimiters (obj / endobj) |
| 1.4.6 | 34.3 | ID in 1st trailer and the last is different |
| 1.2.5 | 32.1 | The length of the stream dictionary and the stream length is inconsistent |
| 7.11 | 31.9 | PDF/A Identification Schema not found |
| 3.1.2 | 31.6 | Some mandatory fields are missing from the FONT Descriptor Dictionary |
| 3.1.3 | 29.4 | Error on the "Font File x" in the Font Descriptor (ed.:font not embedded?) |
| 3.1.1 | 27.2 | Some mandatory fields are missing from the FONT Dictionary |
| 3.1.6 | 17.1 | Width array and Font program Width are inconsistent |
| 5.2.2 | 13 | The annotation uses a flag which is forbidden |
| 2.4.2 | 12.8 | CMYK color space used in the PDF file but the DestOutputProfile isn't CMYK |
| 1.2.2 | 12 | Error on the stream delimiters (stream / endstream) |
| 1.2.12 | 9.5 | The stream uses a filter which isn't defined in the PDF Reference document |
| 1.4.1 | 9.3 | ID is missing from the trailer |
| 3.1.11 | 8.4 | The CIDSet entry i mandatory from a subset of composite font |
| 1.1 | 8.3 | Header syntax error |
| 1.2.7 | 7.5 | The stream uses an invalid filter (The LZW) |
| 3.1.5 | 7.3 | Encoding is inconsistent with the Font |
| 2.3 | 6.7 | A XObject has an unexpected key defined |
| Exception | 6.6 | Preflight raised an exception |
| 3.1.9 | 6.1 | The CIDToGID is invalid |
| 3.1.4 | 5.7 | Charset declaration is missing in a Type 1 Subset |
| 7.2 | 5 | Metadata mismatch between PDF Dictionnary and xmp |
| 7.3 | 4.3 | Description schema required not embedded |
| 2.3.2 | 4.2 | A XObject has an unexpected value for a defined key |
| 7.1.1 | 3.3 | Unknown metadata |
| 3.3.1 | 3.1 | a glyph is missing |
| 1.4.8 | 2.6 | Optional content is forbidden |
| 2.2.2 | 2.4 | A XObject SMask value isn't None |
| 1.0.14 | 2.1 | An object has an invalid offset |
| 1.4.10 | 1.6 | Last %%EOF sequence is followed by data |
| 2.2.1 | 1.6 | A Group entry with S = Transparency is used or the S = Null |
| 1 | 1.6 | Syntax error |
| 5.2.3 | 1.5 | Annotation uses a Color profile which isn't the same than the profile contained by the OutputIntent |
| 1.0.6 | 1.2 | The number is out of Range |
| 5.3.1 | 1.1 | The AP dictionary of the annotation contains forbidden/invalid entries (only the N entry is authorized) |
| 6.2.5 | 1 | An explicitly forbidden action is used in the PDF file |
| 1.4.7 | 1 | EmbeddedFile entry is present in the Names dictionary |
This table does look a bit intimidating (but see this summary of Preflight errors); nevertheless it is useful to point out a couple of general observations:
- Some errors are really common; for instance, error 2.4.3 is reported for nearly 80% of all PDFs in the corpus!
- Errors related to color spaces, metadata and fonts are particularly common.
- File structure errors (1.x range) are reported quite a lot as well. Although I haven't looked at this in any detail, I expect that for some files these errors truly reflect a deviation from the PDF/A-1 profile, whereas in other cases these files may simply not be valid PDF (which would be more serious).
- About 6.5% of all analysed files raised an exception in Preflight, which could either mean that something is seriously wrong with them, or alternatively it may point to bugs in Preflight.
Policy-based assessment
Although it's easy to get overwhelmed by the Preflight output above, we should keep in mind here that the ultimate aim of this work is not to validate against PDF/A-1, but to assess arbitrary PDFs against a pre-defined technical profile. This profile may reflect an institution's low-level preservation policies on the requirements a PDF must meet to be deemed suitable for long-term preservation. In SCAPE such low-level policies are called control policies, and you can find more information on them here and here.
To illustrate this, I'll be using a hypothetical control policy for PDF that is defined by the following objectives:
- File must not be encrypted or password protected
- Fonts must be embedded and complete
- File must not contain JavaScript
- File must not contain embedded files (i.e. file attachments)
- File must not contain multimedia content (audio, video, 3-D objects)
- File should be valid PDF
Preflight's output contains all the information that is needed to establish whether each objective is met (except objective 6, which would need a full-fledged PDF validator). By translating the above objectives into a set of Schematron rules, it is pretty straightforward to assess each PDF in our dataset against the control policy. If that sounds familiar: this is the same approach that we used earlier for assessing JP2 images against a technical profile. A schema that represents our control policy can be found here. Note that this is only a first attempt, and it may well need some further fine-tuning (more about that later).
Results of assessment
As a first step I validated all Preflight output files against this schema. The result is rather disappointing:
| Outcome | Number of files | % |
|---|---|---|
| Pass | 3973 | 26 |
| Fail | 11120 | 74 |
So, only 26% of all PDFs in Govdocs Selected meet the requirements of our control policy! The figure below gives us some further clues as to why this is happening:
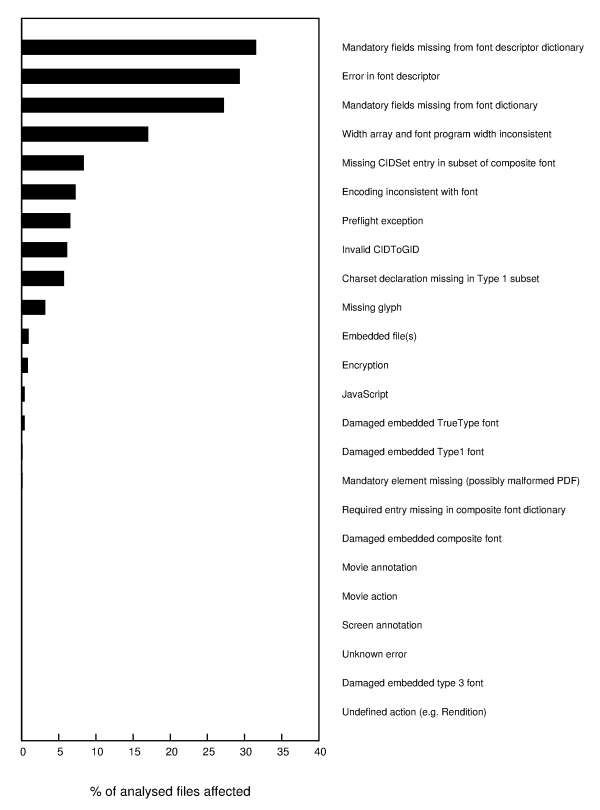
Here each bar represents the occurrences of individual failed tests in our schema.
Font errors galore
What is clear here is that the majority of failed tests is font-related. The Schematron rules that I used for the assessment currently includes all font errors that are reported by Preflight. Perhaps this is too strict on objective 2 ("Fonts must be embedded and complete"). A particular difficulty here is that it is often hard to envisage the impact of particular font errors on the rendering process. On the other hand, the results are consistent with the outcome of a 2013 survey by the PDF Association, which showed that its members see fonts as the most challenging aspect of PDF, both for processing and writing (source: this presentation by Duff Johnson). So, the assessment results may simply reflect that font problems are widespread4. One should also keep in mind that Govdocs selected was created by selecting on unique combinations of file properties from files in Govdocs1. As a result, one would expect this dataset to be more heterogeneous than most 'typical' PDF collections, and this would also influence the results. For instance, the Creating Program selection property could result in a relative over-representation of files that were produced by some crappy creation tool. Whether this is really the case could be easily tested by repeating this analysis for other collections.
Other errors
Only a small small number of PDFs with encryption, JavaScript, embedded files and multimedia content were detected. I should add here that the occurrence of JavaScript is probably underestimated due to a pending Preflight bug. A major limitation is that there are currently no reliable tools that are able to test overall conformity to PDF. This problem (and a hint at a solution) is also the subject of a recent blog post by Duff Johnson. In the current assessment I've taken the occurrence of Preflight exceptions (and general processing errors) as an indicator for non-validity. This is a pretty crude approximation, because some of these exceptions may simply indicate a bug in Preflight (rather than a faulty PDF). One of the next steps will therefore be a more in-depth look at some of the PDFs that caused an exception.
Conclusions
These preliminary results show that policy-based assessment of PDF is possible using a combination of Apache Preflight and Schematron. However, dealing with font issues appears to be a particular challenge. Also, the lack of reliable tools to test for overall conformity to PDF (e.g. ISO 32000) is still a major limitation. Another limitation of this analysis is the lack of ground truth, which makes it difficult to assess the accuracy of the results.
Demo script and data downloads
For those who want to have a go at the analyses that I've presented here, I've created a simple demo script here. The raw output data of the Govdocs selected corpus can be found here. This includes all Preflight files, the Schematron output and the error counts. A download link for the Govdocs selected corpus can be found at the bottom of this blog post.
Acknowledgements
Apache Preflight developers Eric Leleu, Andreas Lehmkühler and Guillaume Bailleul are thanked for their support and prompt response to my questions and bug reports.
Related blog posts
- Identification of PDF preservation risks with Apache Preflight: a first impression
- Identification of PDF preservation risks: the sequel
- Are your documents readable? How would you know? (Duff Johnson)
- From 1 Million to 21,000: Reducing Govdocs Significantly (Dave Tarrant)
- Creating machine understandable policy from human readable policy (Catherine Jones)
- Control Policies in the SCAPE Project (Sean Bechhofer)
-
This was already suggested by this re-analysis of the Acrobat Engineering files that I did in November. ↩
-
This selection was only based on file extension, which introduces the possibility that some of these files aren't really PDFs. ↩
-
Errors that were reported for less than 1% of all analysed PDFs are not included in the table. ↩
-
In addition to this, it seems that Preflight sometimes fails to detect fonts that are not embedded, so the number of PDFs with font issues may be even greater than this test suggests. ↩
February 5, 2014 @ 12:09 pm CET
Dear Johan,
thank you for your blogpost. Tests with PDF in our institution with Preflight and JHOVE have shown pretty similar findings (especially erros due to non-embedded fonts), but I have never run a test with such a big data corpus.
I was hoping to get more insight in the use of the Tool PDF Eh?, because it does seem to be not that trivial for non-tekkies like me.
Which of the files actually starts the GUI Wrapper? Do I have to edit anything, concerning certain paths on my computer, similar to the use of DROID or JHOVE?
Maybe I overlook something really ovbious?
Best wishes,
Yvonne
February 6, 2014 @ 10:55 am CET
In addition to what Johan has said, updating the version in the pom file to 2.0.0-SNAPSHOT may work, however the XML rules are based on the PDFBox Preflight version from the time of the hackathon and will need to be checked to see if they are still current versus newer versions of the library.
February 6, 2014 @ 10:48 am CET
In addition to Will's reply: if I look at the pom.xml of PDF Eh I see a reference to a fairly old version of Preflight, which will miss out on many of the errors that the most recent one is able to detect (Preflight really has improved a lot since that hackathon!). Personally I would be reluctant to use it in its current state.
But you can always use Preflight directly, just download the latest JAR here:
https://builds.apache.org/job/PDFBox-trunk/lastBuild/org.apache.pdfbox$preflight-app/
And then run it using something like:
The scripts at https://github.com/openplanets/pdfPolicyValidate might also be a useful starting point, as it contains all the elements of a minimal QA workflow (I tried to keep it as simple as possible).
February 6, 2014 @ 9:38 am CET
Hi Yvonne,
PDF/Eh? was written at a SPRUCE developers' workshop and hasn't seen any further development since then. Therefore it's not a mature tool and may/may not run very well with large sets of files. As far as I am aware there are no precompiled binaries and to get it to compile/run you need (at least) Maven and JDK7 installed.
Have you tried the tools Johan developed for this blog post? They are available here: https://github.com/openplanets/pdfPolicyValidate
Hope that helps
Will