
This is a relatively long post, so to summarise before delving into the details: We’re exploring Wikidata, the (relatively new) Wikipedia for data, as a knowledge base for digital preservation information and would appreciate feedback and involvement.
At Yale University Library we are beginning a new programme of work (with funding from both CLIR and IMLS) to systematically preserve software to support the long term preservation of our digital collections. One of our long term goals of this work is to enable every digital object under our management to be associated with a representative interaction environment that contains a representative set of software that would have been used to interact with the content during the period when it was first created and used. Through the use of emulation tools and services, such as the bwFLA Emulation as a Service (EaaS) technology, we aim to enable all preserved digital objects to be accessed via these representative rendering environments regardless of the computing environment the end-user is accessing the object(s) from.
An initial stumbling block in this work has been the lack of availability of comprehensive cataloguing tools, databases, and standards for documenting software, and connecting that documentation to other digital preservation information such as file format databases and identification tools. This blog post outlines a possible approach to resolving this issue by implementing a collaborative, trustworthy, and transparent technical information management system within the Wikidata framework.
Previous work and background
Much work has been undertaken in the community over many years to develop multiple technical registries, format information databases, documentation and metadata standards, format identification tools, format assessments, and other digital preservation technical information tools, databases, and services. Many in the digital preservation community have suggested that the community should, and have attempted to, bring this all together in order to make linkages, reduce duplication of work, and gain greater insight through enabling novel and valuable queries to be made across these multiple data sources.
The National Archives of the United Kingdom (TNA) have been a leader in the digital preservation technical information domain for many years now thanks to their work on the Pronom database and the DROID format identification tool. Their contributions have been invaluable and the digital preservation community continues to benefit from the huge amount of work they undertake to develop both the database and DROID, and from their role as editors of digital preservation technical information, in particular of file format documentation and signatures. TNA’s review process within Pronom adds great value to the edits/additions suggested by users through its thoroughness and rules around evidence and verification of the suggested changes. Their process engenders trust in the resulting Pronom database and ensures the community feels comfortable directly using the Pronom data in their production digital preservation systems. The trust that the TNA’s editorial contributions and technical expertise provide in this process must not be overlooked or underestimated for any future implementation or use of TNA’s data as without that trust the data becomes significantly less useful.
Wikidata: a knowledge base & data management system
Wikidata is a knowledge base of structured data that anyone with access to the web can edit. There are two primary components of the data model of Wikidata: items and properties.
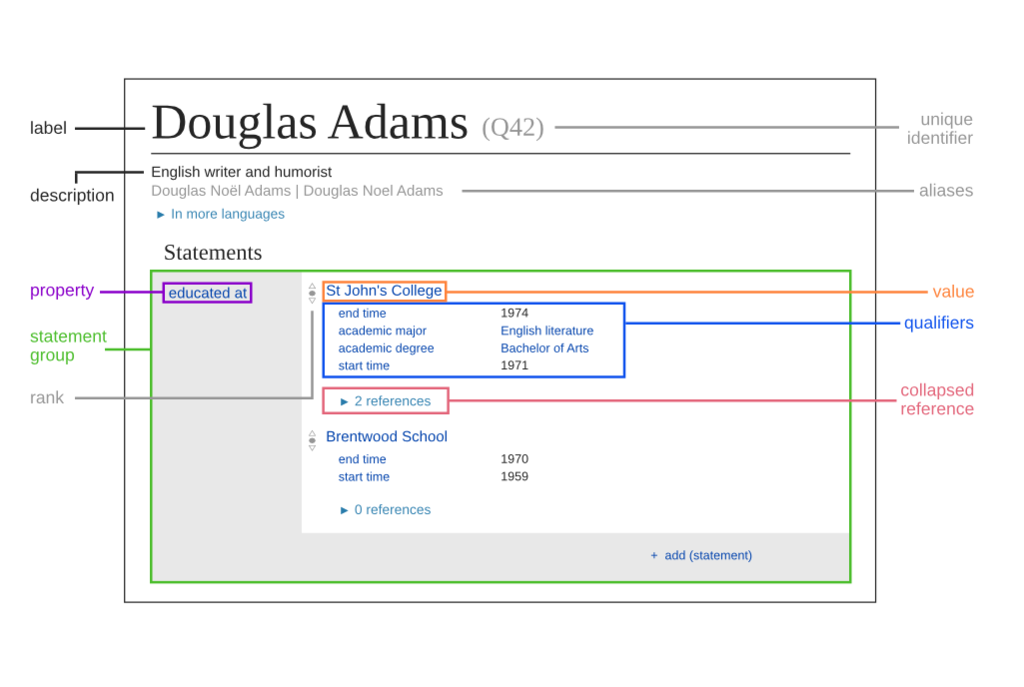
(click image to see larger)
In this figure, the item has the label “Douglas Adams” and the unique identifier of “Q42”. The property is “educated at” and has a value of “St. John’s College”. Editors create statements about items. The resulting structured data is machine-readable linked open data published under a CC0 license, free for anyone to reuse.
Wikidata has many relevant features that it gains from its wiki-heritage that make it much more than just a database and make it very attractive for use as a digital preservation technical information management system. These include a standardized API, the ability to discuss data items using the “talk” page associated with each data item, numerous tools, visualizations, and implementations of Wikidata’s API for various useful purposes, and an ecosystem of existing developers and contributors who can be tapped to work toward achieving the goals of the digital preservation community. Below we explore how these features might be utilized to meet the needs of this community.
Wikidata as a digital preservation technical information data management system
Peter McKinney et al. (2014), introduced the following plan for what a future technical registry might look like. The schematic diagram the authors created is in the image below.
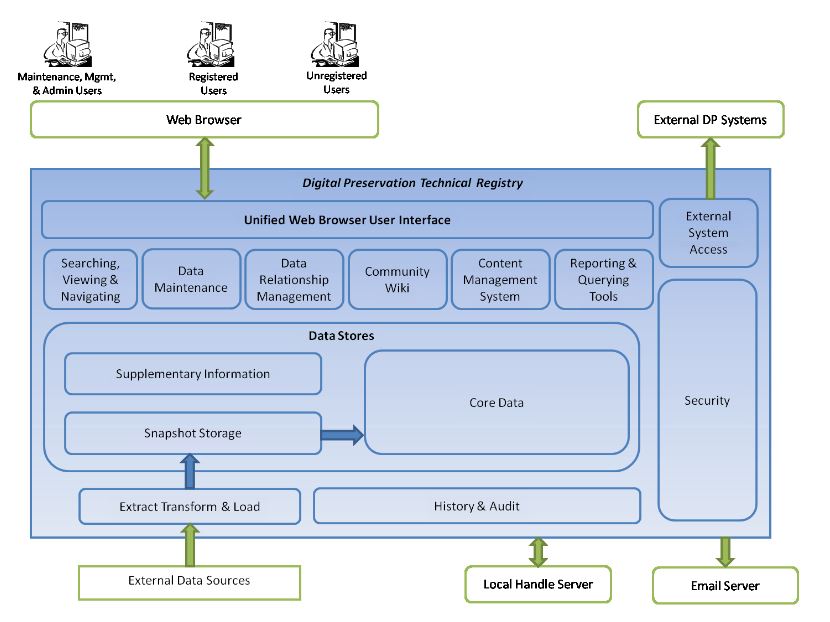
(click image to see larger)
Inspired by this idea, we suggest that the Wikidata infrastructure meets many of the requirements described by McKinney et al. Below we provide some scenarios illustrating how existing data could be added to Wikidata and kept synchronized with its sources. We describe how new data can be added to Wikidata. And finally we discuss how existing and potential infrastructure can be used, reused with modification, or developed with minimal effort to deal with conflicts, engender trust in the data in Wikidata, and build on existing work to quickly provide new interfaces for interacting with digital preservation technical information.
Implementing Totem in Wikidata
TOTEM is the acronym for the Trustworthy Online Technical Environment Metadata Registry created by Janet Delve and David Anderson. The purpose of TOTEM is to establish a standardized set of attributes and relationship descriptor terms to record information about the interrelationships between software and hardware.
In order to implement TOTEM within Wikidata we would need to propose properties for all of the attributes that are described in the TOTEM framework that are not yet available as properties. For example, TOTEM has “processor speed,” “bit width,” “RAM,” “ROM, “motherboard,” as sub-elements to describe hardware configurations we may want to represent. These properties do not currently exist in Wikidata and will need to be proposed.
Properties can be proposed by any Wikidata user. There is a template for property proposals as seen in the image.
(click image to see larger)
After properties are proposed the Wikidata community has the opportunity to ask questions, discuss aspects of the proposal, and vote in support of or opposition to the proposal. The following image is a screenshot of a property proposal discussion.

(click image to see larger)
Due to the fact that Wikidata is a wiki implemented in MediaWiki and Wikibase software, it is fully versioned and all edits are available for review. This means that all discussions among editors can take place on-wiki and remain in the context of the content to which the editors are referring. A versioned system provides value to the digital preservation community in that the work that goes into refining concepts and tools will remain available for anyone to consult at any later point in time. The fact that these discussions would be taking place on a public wiki also means that people from different organizations could collaborate in this forum.
Implementing Pronom in Wikidata
As with the implementation of TOTEM, implementing Pronom in Wikidata will require the addition of a number of properties to the system. Once implemented, a bot could be created and associated with a user account owned by TNA. That bot could regularly synchronize Wikidata based on Pronom data. Once Pronom data was added to Wikidata, non-TNA contributors could then edit Wikidata directly or discuss proposed changes or additions on “talk” pages associated with existing information in the wiki. TNA could regularly query Wikidata to monitor such changes or additions and also use the talk pages to gather more feedback before deciding whether to endorse the changes/additions and add them to the Pronom database. This approach would provide transparency to the editorial process and enable a new form of collaboration on edits to Pronom data.
While investigating the feasibility of this proposed work we discovered to our delight that the Wikidata community has already identified the value of Pronom data. There are already several properties related to concepts relevant to digital preservation in use in Wikidata. Including property 2749 that references Pronom software identifiers.
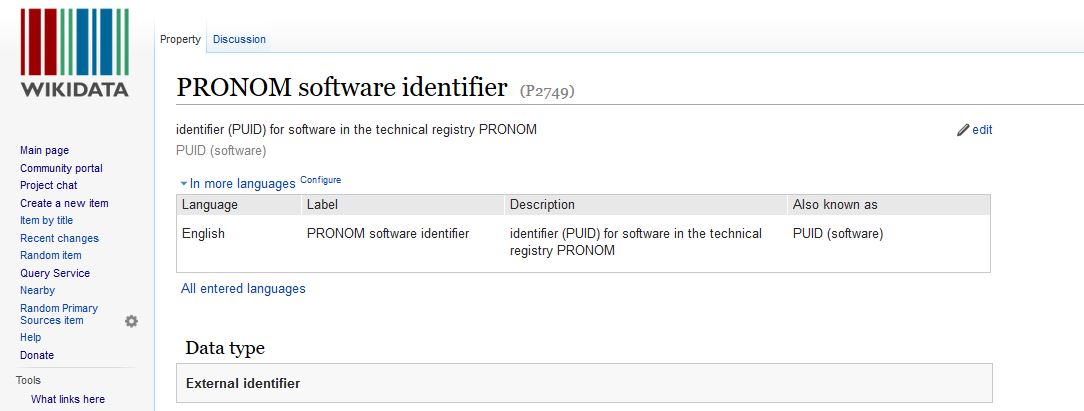
(click image to see larger)
As seen in the image, this property has the data type of external identifier because it references Pronom’s registry. This link provides a SPARQL query we constructed to find the items which have claims asserting P2749 in Wikidata.
In addition the the software identifiers, property 2748 references Pronom file format identifiers.
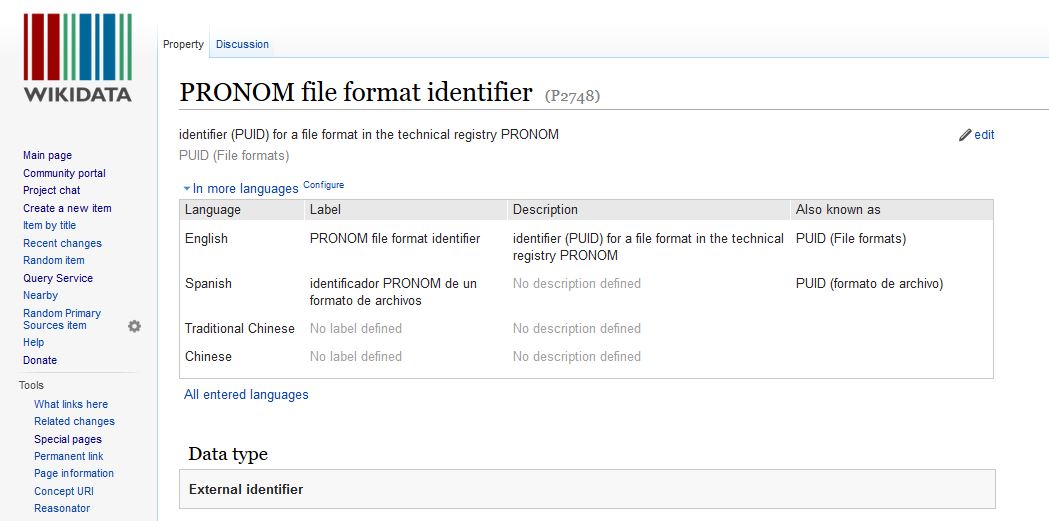
(click image to see larger)
We also wrote a SPARQL query to find all items described by this property in Wikidata.
How conflicts are dealt with in Wikidata
Wikidata is designed to accommodate multiple statements about items, and it is acceptable for those statements to conflict or present differing epistemological views. It is the expectation of the Wikidata community that all claims be referenced to a source, and thus users may determine for themselves how to understand conflicting statements in the context of their sources. One of the advantages of Wikidata is that it is a place for a plurality of views to be organized alongside one another (Vrandečić and Krötzsch 2014: 79), e.g. if you don’t like some data in wikidata, you can add your own as an alternative without disrupting the existing data.
The image below is a screenshot of the Wikidata item for “Chelsea Manning”. In this image we see three statements about Chelsea’s gender, each supported by references. This is an example of how different epistemological views about gender can be accommodated in the Wikidata knowledge base.
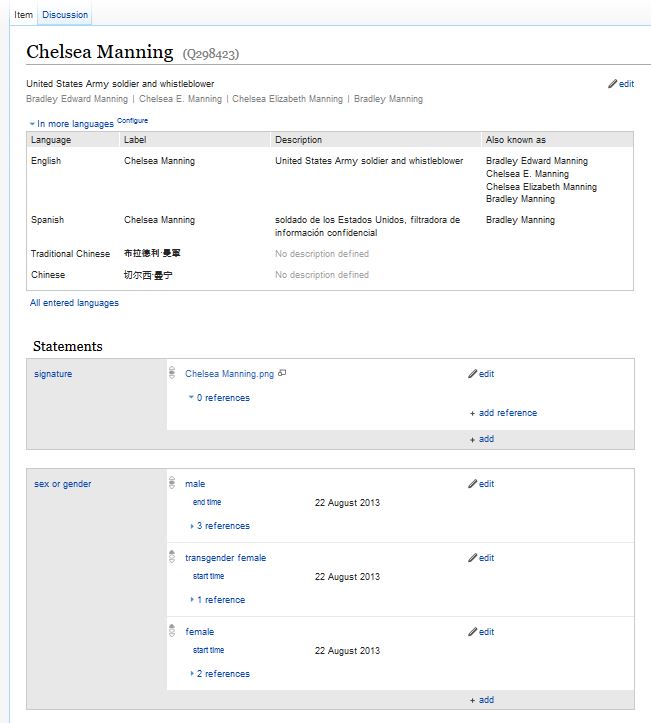
(click image to see larger)
One advantage of incorporating existing file format data into Wikidata would be the opportunity to view data from across multiple registries for each item, as Andy Jackson showed the value of in his various posts, papers, and visualizations. This allows difference in perspectives to be highlighted, interrogated, and potential novel insights to be gained.
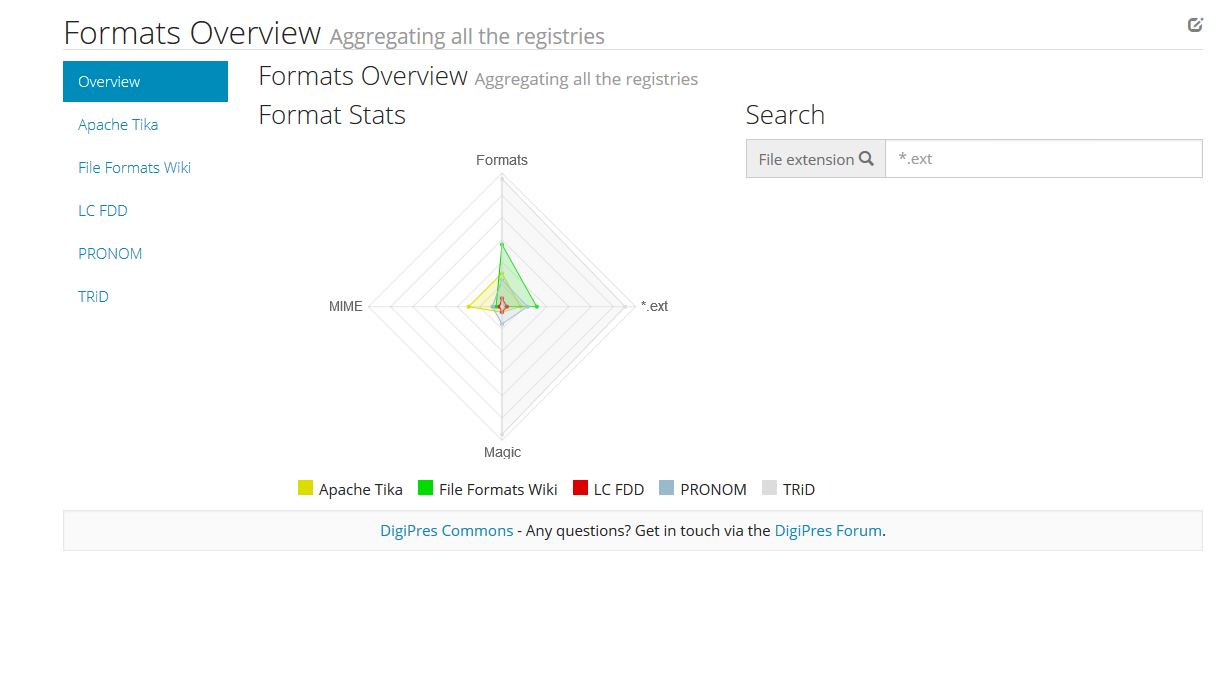
(click image to see larger)
Discussions about differences between views take place on talk pages. The image below is a screenshot of the talk page for the item Q76 “Barack Obama”. Returning to the example of file formats, if the discussions about differences of opinion regarding file formats were to take place on the talk pages of related items on Wikidata, these discussions would be easily re-findable, and would persist for as long as the Wikidata infrastructure is preserved.
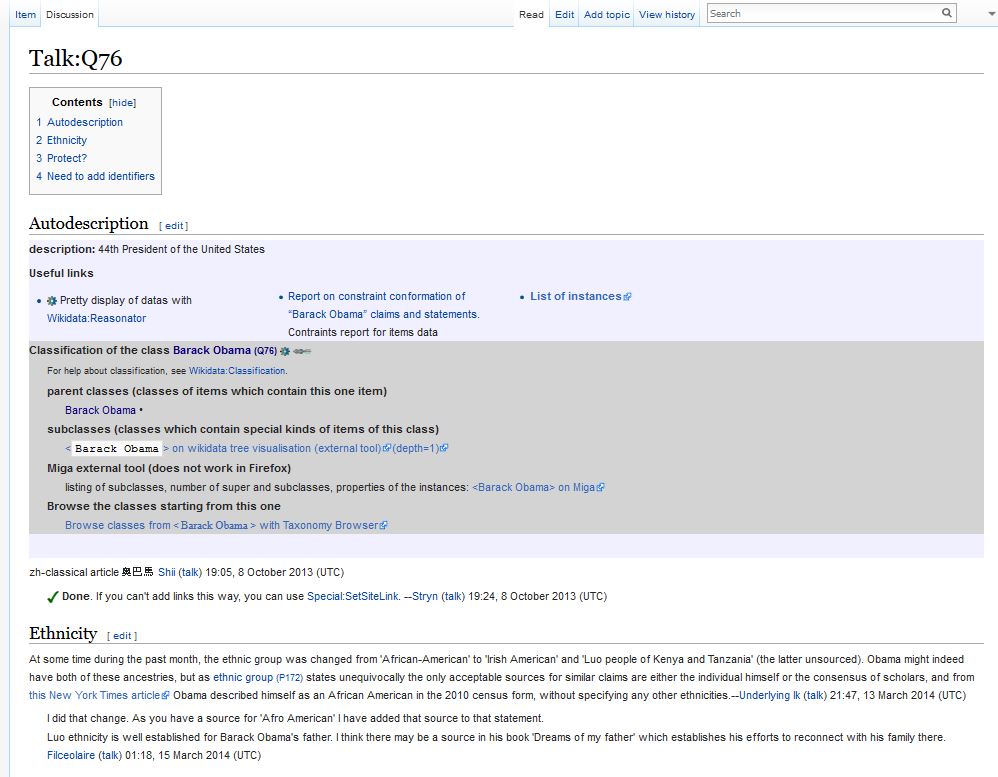
(click image to see larger)
Versioning and Trust in wikidata
Given that anyone can edit Wikidata, if the digital preservation community wants to rely on the information in Wikidata and use it within production systems and workflows, we will need robust solutions to issues of trustworthiness and accuracy of information. One approach we are investigating is to use trusted user accounts to identify trustworthy content. These accounts could be accounts with verifiable affiliations to individuals or organizations known to members of the digital preservation community. An example of this might be a Wikidata account named “YaleUniversityLibraryDigitalPreservation” in which our department describes our professional credentials and active projects on the user page for the account. Another example might be a bot account used to programmatically edit Wikidata via the API.
It is possible to edit Wikidata without an account. The IP address from which the user is connecting is recorded in the edit history for anonymous contributions. The majority of users create accounts, and their username is recorded in the Wikidata edit history as they save their changes to the knowledge base.
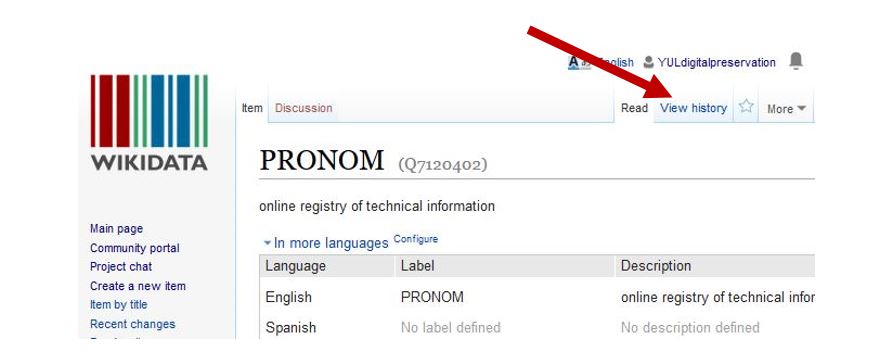
(click image to see larger)
Edit histories are publicly available in Wikidata. For item Q7120402 “Pronom,” the edit history is available by clicking the “View history” tab, as illustrated in the image.
Users of digital preservation information in Wikidata could choose to only trust edits by accounts with which they have familiarity or other reasons to trust. To identify trustworthy edits that are trustworthy but not created by an already-trusted user, one option may be for trusted users to use property P790 “approved by” to “endorse” edits made by others, edits that they (the trusted user) approve.
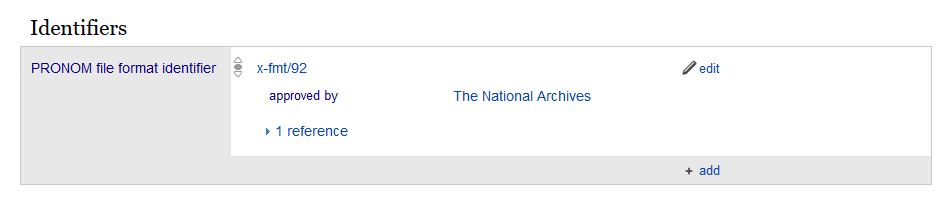
(click image to see larger)
Trustworthiness of data will be important in the potential success of this proposal so it is worth spending some more time/screen real estate elaborating on this point. The most likely implementation scenario for this trust mechanism would occur when users of Wikidata data made use of the Wikidata API to access data for use in their local systems. Users would query the Wikidata API with a request to return only the most recent version of data items that have been edited by one of a set of trusted users. This query, for example, returns the most recent revisions to the “.psd” page. The “revisions” section shows the users who edited the page and the “rev/diff” section shows what change they made. The diff section parsed to HTML shows that the “approved by: The National Archives” section was removed then added back:

(click image to see larger)
Such a scenario would not preclude other not-yet-trusted users making changes to digital preservation data in Wikidata. If user accounts that are not yet trusted by the digital preservation community make additional statements about items we are interested in, or revise statements we have already found to be trustworthy, we could choose not to automatically accept these edits for inclusion into workflows we create that pull data from Wikidata. The “talk” page for each data item could also then be used to discuss the changes that non-trusted editors made and to e.g. request more information. Trusted users and contributors, such as The National Archives, might chose to monitor edits to data items they care about by creating and regularly running API queries that monitor for changes to those data items. Those changes could then be validated by the National Archives in Wikidata, using their account, and added to the Pronom database, or the National Archives could add the editor to their trusted editors list and notify the rest of the community that they endorse that editor and their edits so others could do the same and update their own queries.
A more effective (and wiki-like) solution than using the combination of API and SPARQL endpoint for monitoring, endorsing, and enabling trust of edits in Wikidata may be to lobby the Wikidata community to enable the creation of statements about Wikidata statements within Wikidata itself. This would enable a contributor such as the National Library of New Zealand to endorse statements, or versions of statements, that they trust. E.g. endorsing the statement that that ““xxxxx” is the signature for the .docx format as created by Microsoft Office 2007”, and have that endorsement queryable via the SPARQL endpoint alone. Fortunately for us, a technical mechanism for achieving this already exists. The “Semantic History” extension, was available in the Semantic Mediawiki framework, a precursor to Wikidata and could be used as a precedent and technical guidance for implementing a similar approach in wikidata.
Example SPARQL queries
The Wikidata SPARQL endpoint maintains a list of example queries (available from the “Examples” button). Once a SPARQL query has been written it can be reused by others to find updated results. A member of the digital preservation community has written a SPARQL query to answer questions such as:
- I want to know all formats in Wikidata that don’t have property ‘y’
- I want all open source software that can render x and runs on operating system ‘z’
Other members of the community could then reuse these queries to quickly and easily leverage the infrastructure to answer relevant questions. We could all benefit from the work of a few SPARQL query writers and be able to answer many different types of data-driven questions.
Portal development
As mentioned, significant existing infrastructure exists for working with Wikidata data that has the potential for rapid repurposing for digital preservation use-cases. We are exploring the potential of reusing some of this infrastructure to create a digital preservation portal that would streamline contributing data and metadata, relevant to communities concerned with the preservation of digital content, and enable querying and reporting on that data.
The portal “The Centralized Model Organism Database” created by members of the Su Lab for the biomedical sciences to support curation of model organism data looks like a good starting point for the development of a digital preservation portal. The Centralized Model Organism Database is described starting from slide 14/34 in the slide deck from Benjamin Good and Timothy E. Putman and discussed in the video here. The code for that portal is available online and has the potential to be fairly quickly repurposed to meet digital preservation use-cases such as as a cataloguing tool for software, emulated hardware, and configured emulatable/virtualizable environments.
Yale University Library needs an effective set of tools for meeting our software preservation needs. However if a portal were to be developed we would aim to develop a sustainable model for the support and maintenance of the portal over time (potentially collaborating with the Open Preservation Foundation to maintain the portal). Fortunately any data created or edited via the portal will have inherent sustainability through the peer-production model of software development used by the Wikimedia foundation and the much larger global community that continues to support Wikidata over time.
Potential insights/queries enabled by using Wikidata for digital preservation
As many have discussed previously, bringing together data from multiple existing registries and databases enables novel uses of that data. Doing this in Wikidata adds additional value through the existing data and links already in Wikidata and through the relationship between Wikidata and Wikipedia which enables further novel uses.
Below we list a number of possible future use-cases for digital preservation data within Wikidata (in no particular order) to give readers a vision of the potential future value of this proposed approach.
- I want to identify all software that is known to “render” or enable interaction with a particular format
- I want to identify all emulatable software that created (and probably renders) software-defined sub-formats
- I want to add a “controversial” sub-format, defined by its creating application, e.g. Open document spreadsheet files created by office 2007, open document spreadsheet files created by openoffice 2.x, etc to the database without changing the primary format record
- I want to get all LoC format data and Pronom data for use in my file ID tool, but preference LoC signatures
- I want to get all software documentation from Wikipedia that relates to this particular software that renders this particular format, so I can present it alongside the emulated instance of the software
- I want to catalogue a new piece of software
- I want to catalogue a configured emulatable environment with software installed.
- I want to catalogue an emulator and document what hardware configurations it can emulate
- I want to change a file format signature as I think the current one is wrong/not the best it could be
- I want to add a sub-format based on creation software
- I want to be notified whenever records are updated by the Pronom bot
- I want to be notified whenever my edits are changed
- I want to identify all software that has a command line interface or API and that can also be used to migrate between fmt/353 (TIFF) and fmt/479 (PDF-A v3a
- I want to know if any applications differentiate between Microsoft word for DOS versions 4.x and 5.x in their open-as and save-as parameters (as if they don’t then this implies that they are functionally the same format).
- I want to know the end-of support date for every software application used to create every file format I have instances of in my digital preservation system, and whether there is an emulatable environment containing the software available somewhere.
- I want to know:
- For all software applications documented in Wikipedia that we know went ‘obsolete’ within the lifetime of Wikipedia, how often are the pages updated and were they updated after the software became ‘obsolete’ (e.g. out of support)
- How often the Wikipedia page for a particular software program (the only one that renders a format I have in my repository) has had manual edits made to it, and how recently it had an edit, in order to identify whether it has likely gone obsolete.
- I want to know all organizations that use Sigfreid, DROID, JHOVE etc
Next steps
We’re currently seeking feedback on this proposed approach. Provided no major issues are uncovered we will be pursuing it at Yale University Library and will soon begin proposing properties to build out the digital preservation model in Wikidata. We’ve created a Google group where we will share updates about our work on this and invite collaboration on the proposal process for new properties to be created in Wikidata. The name of the group is “wikidata-for-digital-preservation”. If you are interested in participating collaboratively please navigate through to that link and request to be added to the group and we will add you. We would love to have a wide range of voices contributing to this proposed approach and would value a diversity of input. As and when we move forward with this we will ask for collaboration on developing the necessary properties to describe software, hardware, operating systems, emulated environments, file formats, etc. We will also seek input on any portal development work we initiate.
Please also sign up for a Wikidata account if you don’t already have one (Wikipedia accounts can be used on Wikidata), take a look at the queries we’ve linked to above and, if you’re particularly motivated, try adding some details to one of the file format data items to get started with contributing to the global community resource that Wikidata represents. Given Wikidata is an open system, you can also ignore our work completely if you’d like, and start proposing new relevant properties and using the knowledgebase for your own purposes also. We certainly encourage use of Wikidata as the more data that gets added to it the more value we can all get from the knowledge base as a whole.
The community, existing infrastructure, and links that Wikidata provides, along with the sustainability of the Wikimedia foundation, do seem to imply this approach has value. We see a lot of potential value in this proposed work but want to ensure that it’s not just re-implementation of previous approaches in a new set of infrastructure. While any additions we make at Yale to Wikidata will be maintained indefinitely by the Wikidata community and not be “wasted” we would love this work to have value for the whole digital preservation community, and for this use of Wikidata to evolve into something the community all contributes to, gets value from, and “owns”. For these reasons very much welcome any and all feedback and involvement. In particular there are a few pressing thorny issues to work through regarding trust and extending and connecting/mapping the existing information models when implementing them in Wikidata, and we know the community has a lot of expertise that could be brought to bear on these. So please either comment below or join the Google group and start a discussion.
Katherine Thornton and Euan Cochrane


{kind=link}
October 6, 2016 @ 2:01 pm CEST
@christiankl I’ve submitted feedback to the open preservation foundation about your issues with creating an account and logging in. Thanks for your feedback!
October 5, 2016 @ 1:50 pm CEST
@sfauconn: Thank you very much for sharing the link to that Phabricator task. I was not aware of it and it is relevant to this topic. I do not yet have an account on Phabricator, perhaps this is the opportunity to create one in order to provide feedback about this proposal. Thanks again for pointing this out.