
The British Library’s Digital Preservation Team is sometimes asked to help resolve the preservation planning challenges of Library colleagues and other organisations. This post describes a recent request for assistance, the steps taken to learn more, the conclusions reached, and where this leads us next.
The TIFF format and lossless compression
The TIFF image format is generally regarded as the gold standard for long-term storage of static image data. It is flexible, widely supported, and rich in its treatment of both image data and metadata. Its historical disadvantage has been its large file sizes; this can, however, be mitigated by the use of compression, support for which is built into the format and described in the TIFF compression tag for each file.
The method most commonly used to compress TIFF files is the Lempel-Ziv-Welch algorithm, or LZW, which has been supported since 1988. Since then support has been introduced for other compression methods, including the one which we were asked to investigate as to its effectiveness – namely Deflate, more commonly referred to as Zip compression. Zip compression has been widely implemented since its initial development, due primarily to the fact that the general algorithm itself remains unpatented. LZW, by contrast, remained under patent util 2003, limiting its widespread adoption except where used under license.

Our challenge
The Digital Preservation Team were contacted by colleagues who wanted to know how much space could be saved by introducing compression to the TIFF files in their archives. They did not know what proportion of their files might already be compressed, or what compression method might be the most effective – indeed, whether a mix of different compression methods might provide the greatest savings overall.
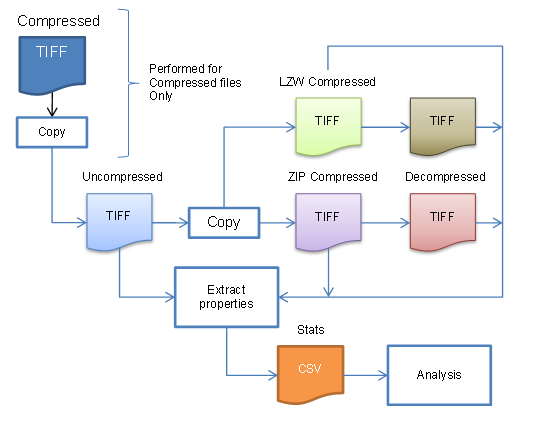
We took a sample of just over 500 files from 17 different collections, containing a mix of colour and monochrome images. The collections included a wide variety of content – photographs, manuscripts, microfilm, newsprint and magazines to name but a few. Then we developed a shell script to take each TIFF file through the following steps:
- Strip existing compression, if necessary – saving the original file
- Create LZW-compressed copy of file
- Create Zip-compressed copy of file
- Decompress LZW-compressed copy of file as new file
- Decompress Zip-compressed copy of file as new file
- Extract critical image properties (e.g. size, colour depth, etc) for each file
- Save the details of each image to a CSV file, ready to crunch the numbers
Our results
Using all the information we had collected, we were able to perform a detailed analysis of the compression and decompression process and reached the following high-level conclusions with respect to our sample.
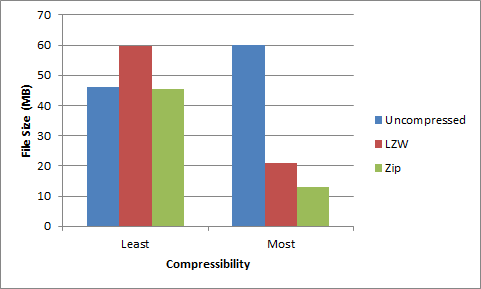
- Zip compression always resulted in a smaller file than the original.
- LZW compression sometimes resulted in a larger file than the original.
- Zip compression was uniformly more effective than LZW compression.
- Base image properties (size, colours) were retained.
- Decompressed files were not always the same size as the original.
The next steps
These results were interesting in themselves but also led us to explore more deeply. In particular we were keen to investigate variations in file compressibility, comparisons of different compression tools, and the size difference between uncompressed and decompressed files.
These and other findings will be discussed at length in our forthcoming paper on TIFF compression – release date yet to be announced.
Watch this space for news!

