
From the very beginning of the SCAPE project on, it was a requirement that the SCAPE Execution Platform be able to leverage functionality of existing command line applications. The solution for this is ToMaR, a Hadoop-based application, which, amongst other things, allows for the execution of command line applications in a distributed way using a computer cluster. This blog post describes the combined usage of a set of SCAPE tools for characterising and profiling web-archive data sets.
We decided to use FITS (File Information Tool Set) as a test case for ToMaR for two reasons: First, the FITS approach of producing “normalised” output on the basis of various file format characterisation tools makes sense, and therefore, enabling the execution of this tool on very large data sets will be of great interest for many people working in the digital preservation domain. Second, the application is challenging from a technical point of view, because it starts several tools as sub-processes. Even if a process takes only one second per file, we have to keep in mind that web archives usually have potentially billions of files to process.
The workflow in figure 1 is an integrated example of using several SCAPE outcomes in order to create a profile of web archive content. It shows the complete process from unpacking a web archive container file to viewing aggregated statistics about the individual files it contains using the SCAPE profiling tool C3PO:
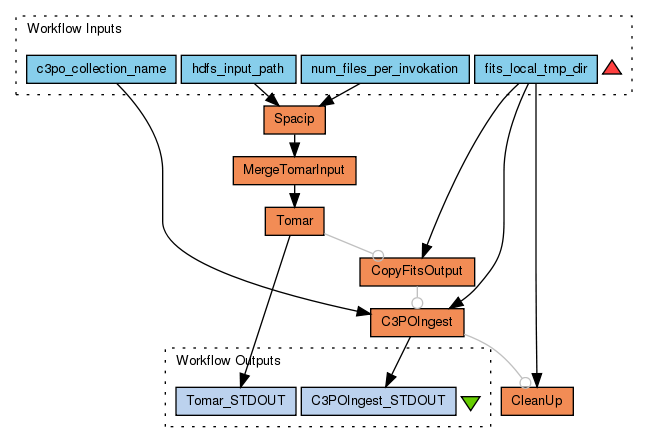
Figure 1: Web Archive FITS Characterisation using ToMaR, available on myExperiment: www.myexperiment.org/workflows/3933
The inputs in this worklow are defined as follows:
-
“c3po_collection_name”: The name of the C3P0 collection to be created.
-
“hdfs_input_path”, a Hadoop Distributed File System (HDFS) path to a directory which contains textfile(s) with absolute HDFS paths to ARC files.
-
“num_files_per_invocation”: Number of items to be processed per FITS invocation.
-
“fits_local_tmp_dir”: Local directory where the FITS output XML files will be stored
The workflow uses a Map-only Hadoop job to unpackage the ARC container files into HDFS and creates input files which subsequently can be used by ToMaR. After merging the Mapper output files into one single file (MergeTomarInput), the FITS characterisation process is launched by ToMaR as a MapReduce job. ToMaR uses an XML tool specification document which defines inputs, outputs and the execution of the tool. The tool specification document for FITS used in this experiment defines two operations, one for single file invocation, and the other one for directory invocation.
FITS comes with a command line interface API that allows a single file to be used as input to produce the FITS XML characterisation result. But if the tool were to be started from the command line for each individual file in large a web archive, the start-up time of FITS including its sub-processes would accumulate and result in a poor performance. Therefore, it comes in handy that FITS allows the definition of a directory which is traversed recursively to process each file in the same JVM context. ToMaR permits making use of this functionality by defining an operation which processes a set of input files and produces a set of output files.
The question how many files should be processed per FITS invocation can be addressed by setting up a Taverna experiment like the one shown in Figure 2. The workflow presented above is embedded in a new workflow in order to generate a test series. A list of 40 values, ranging from 10 to 400 in steps of 10 files to be processed per invocation is given as input to the “num_files_per_invocation” parameter. Taverna will then automatically iterate over the list of input values by combining the input values as a cross product and launching 40 workflow runs for the embedded workflow.
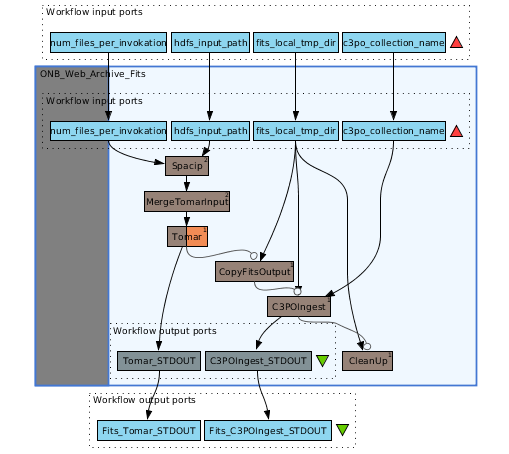
Figure 2: Wrapper workflow to produce a test series.
5 ARC container files with a total size of 481 Megabytes and 42223 individual files were used as input for this experiment. The 40 workflow cycles were completed in around 24 hours and led to the result shown in figure 3.
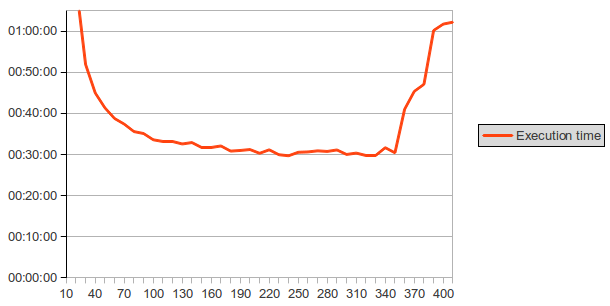
Figure 3: Execution time vs. number of files processed per invocation.
The experiment shows a range of values with the execution time stabilising at about 30 minutes. Additionally, the evolution of the execution time of the average and worst performing task is illustrated in figure 4 and can be taken into consideration to choose the right parameter value.
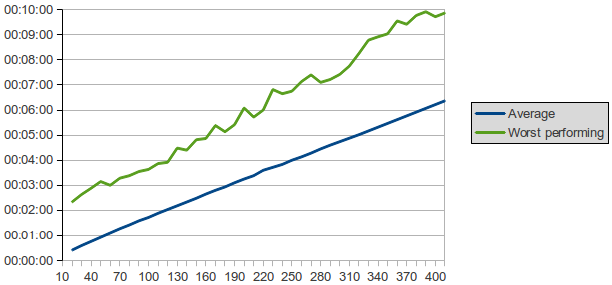
Figure 4: Average and worst performing tasks.
As a reference point, the 5 ARC files have been processed locally on one cluster node in a single-threaded application run in 8 hours and 55 minutes.
The cluster used in this experiment has one controller machine (Master) and 5 worker machines (Slaves). The master node has two quadcore CPUs (8 physical/16 HyperThreading cores) with a clock rate of 2.40GHz and 24 Gigabyte RAM. The slave nodes have one quadcore CPUs (4 physical/8 HyperThreading cores) with a clock rate of 2.53GHz and 16 Gigabyte RAM. Regarding the Hadoop configuration, five processor cores of each machine have been assigned to Map Tasks, two cores to Reduce tasks, and one core is reserved for the operating system. This is a total of 25 processing cores for Map tasks and 10 cores for Reduce tasks. The best execution time on the cluster was about 30 minutes which compares to the single-threaded execution time as illustrated in figure 5.
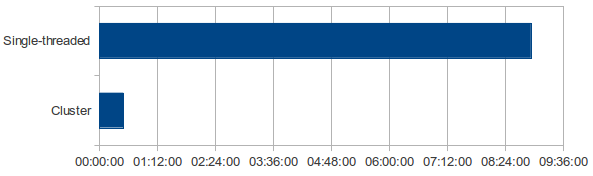
Figure 5: Single-threaded execution on one cluster node vs. cluster execution.
Processing larger data sets can be done in a similar manner to the one that is shown in figure 2, only that a list of input directory HDFS paths determines the sequence of workflow runs and the number of files per FITS invocation is set as a single fixed value.
The following screencast shows a brief demo of the workflow using a tiny arc file containing the harvest of an HTML page referencing a PNG image. It demonstrates how Taverna orchestrates the Hadoop jobs using tool service components.
