
Organisations that use JHOVE for PDF validation will already be familiar with the number of error messages it reports. The recently released JHOVE v1.16 Release Candidate (RC) includes a couple of my bug fixes for the PDF module which appear to reduce this number significantly. These fixes were the result of investigating “Invalid Page Dictionary Object” errors and then a subsequent “Improperly Constructed Page Tree” error (which seemed to result from having solved the former).
Prior to this RC, Kevin Davies and I performed a short evaluation of the bug fixes against three (BL-internal) PDF samples (2,759 PDFs total) – one eBook set (set 2) and two eJournal set (sets 1 and 3). We wanted to understand the impact these code changes had on the reported error messages, in particular whether they reduced the error messages for which they were targeting.
This post summarises that brief analysis, highlights the fixes, and makes suggestions about what this may mean for software used in digital preservation – spoiler: it needs testing and we need to make that happen!
What have the fixes achieved?
Before discussing what modifications were made, let’s first indicate what effect it has on the sample sets of PDFs.
The figure below shows a breakdown of JHOVE responses for each of the three sample sets, comparing the patched JHOVE v1.15 code against the v1.15 codebase immediately prior to patching. As you can see there is some variation between the test sets, but overall they show a dramatic reduction in the number of “Not well-formed” results and a significant increase in the number of “Well-formed and valid” responses.
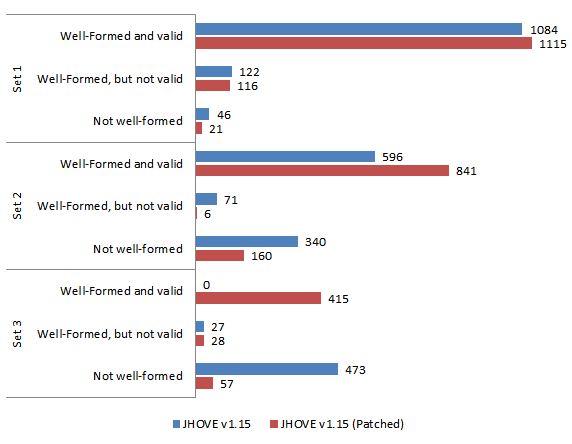
Comparing the responses for all files, we see – for all but 1 file (in Set 2) – a positive movement in their classification from “Not well-formed” (NWF) to “Well-formed but not Valid” (WF-NV) to “Well-formed and valid” (WF-V). For example, in the case of Set 3:
- 404 files upgraded from NWF to WF-V
- 12 files upgraded from NWF to WF-NV
- 57 files remained NWF
- 11 files upgraded from WV-NV to WF-V
- 16 files remained WF-NV
- 0 files downgraded
This movement is the same for the other sets, except in Set 2 where 1 file is “downgraded” from WF-NV to NWF; the cause of this is yet to be investigated.
Delving into these results a little more and focusing on the error messages that initiated the patch – Invalid Page Dictionary Objects and Improperly Constructed Page Trees – the results show that the patch completely eliminates occurrences of these error messages:
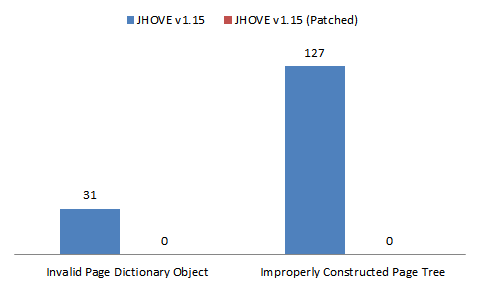
Without knowing anything about the patch or the sample PDFs, this of course opens up questions about whether such results are the correct results, but we’ll get to that…
Assuming our aim is to reduce incidence of erroneous error messages, on the whole then, the JHOVE patch appears to be working insofar as the intended error messages. Given the number of files that have had their overall status changed (fig 1), however, the results also hint that they affect more than just Invalid Page Dictionary Object and Improperly Constructed Page Tree errors.
Expanding to look at all the error messages reported by the JHOVE v1.15 and the patched version, we see that the patches have caused similar eliminations across a wider set of messages. Continuing to focus on Set 3 alone, Table 1 shows the extent of the reduction in error counts across all the error messages reported for that set. Of the 27 listed error messages, 15 have been eliminated from being reported, and 1 has been reduced from 6 incidences to 1 (Invalid Outline Dictionary Item). Similar results are seen for the other 2 sets (see the summary of JHOVE error messages Spreadsheet).
|
JHOVE v1.15 |
JHOVE v1.15 (Patched) |
|||
| JHOVE Error Message | #Messages | #Files | #Messages | #Files |
| Expected dictionary for font entry in page resource | 360 | 360 | 0 | 0 |
| Invalid Annotation property | 118 | 118 | 0 | 0 |
| Annotation object is not a dictionary | 83 | 83 | 0 | 0 |
| Improperly constructed page tree | 43 | 35 | 0 | 0 |
| Invalid object number in cross-reference stream | 40 | 40 | 40 | 40 |
| Invalid page tree node | 19 | 19 | 0 | 0 |
| Invalid page dictionary object | 15 | 15 | 0 | 0 |
| Invalid object number or object stream | 12 | 11 | 0 | 0 |
| Improperly formed date | 8 | 8 | 8 | 8 |
| Malformed dictionary | 8 | 8 | 8 | 8 |
| Invalid outline dictionary item | 6 | 6 | 1 | 1 |
| Invalid dictionary data for page | 6 | 6 | 0 | 0 |
| Invalid Resources Entry in document | 6 | 5 | 0 | 0 |
| Invalid Annotations | 5 | 5 | 0 | 0 |
| Compression method is invalid or unknown to JHOVE | 4 | 4 | 4 | 4 |
| edu.harvard.hul.ois.jhove.module.pdf.PdfInvalidException: Invalid destination object | 4 | 3 | 31 | 14 |
| Unexpected exception java.lang.ClassCastException | 3 | 3 | 0 | 0 |
| Malformed filter | 3 | 3 | 3 | 3 |
| Invalid destination object | 3 | 3 | 5 | 5 |
| Annotation dictionary missing required type (S) entry | 3 | 3 | 0 | 0 |
| Malformed outline dictionary | 2 | 2 | 0 | 0 |
| Improperly nested array delimiters | 1 | 1 | 1 | 1 |
| Invalid Font entry in Resources | 1 | 1 | 0 | 0 |
| Invalid character in hex string | 1 | 1 | 1 | 1 |
| Missing expected element in page number dictionary | 1 | 1 | 1 | 1 |
| Outlines contain recursive references. | 74 | 74 | 0 | 0 |
| Too many fonts to report; some fonts omitted. | 1 | 1 | 4 | 4 |
In general, these results indicate that there appear to have been a large number files erroneously being reported as invalid due to bugs in JHOVE. These appear to have been resolved by the code modifications, but this opens up the question of whether this reduction in error counts is the correct behaviour? My colleagues in the Library and in the OPF have reviewed my patches from a coding perspective and have confirmed the modifications are correct. Equally the PDF experts at Dual Lab (the development team who brought you veraPDF) have evaluated the changes with reflection on the actual validity of test PDFs and have also given it a thumbs up.
Not all error messages were reduced or eliminated, however. A couple of messages show a small increase in the number of incidents – “Invalid Destination Object”, “Too many fonts to report; some fonts omitted”, and (for another set) “Malformed Filter” errors. These need further investigation to determine what their cause is; either it’s another bug that’s only become apparent by the correction of the coding bugs (in much the same way that the Improperly Constructed Page Tree only became apparent after the Invalid Page Dictionary Object error was corrected), or these files do indeed have problems related to these new error messages that were being masked by the patched errors.
What were the bugs? Why have they had such an effect on other error messages?
The bugs were quite low-level in the code and, as I was coming at it fresh to the codebase and the PDF spec, took a while to track down – roughly 3 days (including time to read up parts of the PDF spec). Having identified them and worked them through, they now seem fairly obvious corrections; this goes to show just how difficult it can be to build and maintain robust software.
My investigation started with looking at a file exhibiting the Invalid Page Dictionary Object error.
Invalid Page Dictionary Object
Invalid Page Dictionary Object error is reported when the PDF Pages Dictionary (the root of the Page Tree) is not found or has somehow been corrupted (tested by it not being a valid PDFDictionary object).
Unfortunately, in occasions when the PDF’s Page Tree is Flate encoded in a stream object and where the root page starts beyond one stream buffer’s worth of data, this error is also reported. This is caused by a mistake (typo?) in the PdfFlateInputStream.skipIISBytes method which miscalculates the number of bytes in the stream to skip when the requested skip number is larger than the remaining buffer size.
@@ -314,15 +314,15 @@ public class PdfFlateInputStream extends FilterInputStream { /** Skip a specified number of bytes. */ private long skipIISBytes (long n) throws IOException { if (iisBufOff >= iisBufLen && !iisEof) { readIIS (); } if (iisEof) { return -1; } if (iisBufLen - iisBufOff < n) { - n = iisBufLen + iisBufOff; + n = iisBufLen - iisBufOff; } iisBufOff += n; return n; }
Specifically, line 324 of PdfFlateInputStream should set the skip amount to be the amount of data left (by subtracting the difference between buffer length and current offset). Instead the amount skipped was being set to the buffer length plus the current offset into that buffer – i.e. the skip jumps beyond the length of the buffer.
Having corrected for that error (see patch above), JHOVE then typically reports an Improperly Constructed Page Tree.
Improperly Constructed Page Tree
This error gets reported when there’s a problem iterating through JHOVE’s internal model of a PDF’s Page Tree. Specifically, JHOVE records a list of Page Object IDs that it visits whilst iterating through, and if an ID reoccurs, it reports that the Page Tree was not constructed properly.
This sounds sensible. Unfortunately, it was possible for a Page Object to not get its ID set when the object was located in an Object Stream (line 2429 in PdfModule simply returned the Object without setting it’s ID); in this case its ID reverted to the default (-1). With no checks being made for -1 IDs when iterating the Page Tree model, a second occurrence of a Page Object with a -1 ID causes the Improperly Constructed Page Tree error to be reported.
The fix (which David Russo improved upon from my initial implementation) is to ensure that the Object’s ID is set when trying to retrieve that specific Object (see line 128 in ObjectStream)
@@ -116,21 +116,24 @@ public class ObjectStream { /** Extracts an object from the stream. */ public PdfObject getObject (int objnum) throws PdfException { Integer onum = new Integer (objnum); Integer off = (Integer) _index.get (onum); try { if (off != null) { int offset = off.intValue (); _parser.seek (offset + _firstOffset); - return _parser.readObject (false); + PdfObject object = _parser.readObject (false); + /* Need to ensure the object number is set */ + object.setObjNumber(objnum); + return object; } return null; } catch (IOException e) { throw new PdfMalformedException ("Offset out of bounds in object stream"); } } }
Why should the bugs have an effect on other error messages then? Ultimately, the bugs themselves are in low-level parts of code that affect the handling of Flate encoded stream objects. The error in skipIISBytes method, in particular, will cause issues navigating around such stream objects (e.g. seeking to specific offsets), which impact the ability for JHOVE to process them. Therefore the other errors reported are likely to be the result of this failure.
What does this mean for JHOVE and more generally for software used in digital preservation?
Foremost, the software we use needs to be tested and re-tested as and when changes are made to it.
As far as JHOVE is concerned, it appears that it has erroneously been reporting many PDFs as invalid – but there was no reason to suspect these outputs were incorrect. The changes to the code described above seem to be a positive step forwards in reducing these occurrences; however, despite these changes having had numerous people review them, it is still hard to be conclusive about an improvement without adequate testing against a suitable, open, ground-truthed corpus of test files. How else will we know if the software has been correctly developed to produce the correct output?
Developing software is difficult, period. It’s harder still to develop robust software that correctly handles every variation in input. And it’s even harder when development effort is being done in people’s spare time, split around day jobs, etc. Without focused effort, coding errors creep in, go easily unnoticed, and can be difficult to find even when you are looking (regardless of how simple they may seem once found).
With no slight on JHOVE’s developers, the fact that bugs appear to have been found in JHOVE is not a surprise; I would expect them in any large and complicated piece of software. And so it is perhaps a good idea for us to assume that bugs exist in any of the software we intend to use. Some software will be better than others, of course, and this will generally be related to the amount of testing that has gone into its development. Does JHOVE need better testing? Sure it does!
So, with this assumption in mind, what can we do to help assure ourselves that tools are working effectively? And what else can we do to mitigate preservation problems relating to software – such as from files erroneously marked as invalid?
- Test them! Build up unit tests and testing frameworks for tools; evaluate new versions and updates to software; ensure all tests pass.
- Develop open, ground-truthed, test suites so that we can verify the output from software testing.
- Perform in-house testing and report summary results to developers and/or the community, particularly where sample files cannot be shared, so as to provide a community confidence level in the software.
- Compare tools against one another to see where differences of opinion lie (how does JHOVE validation compare against other tools?), promoting confidence in software and direction for further development.
- Provide dedicated in-house developer resource to support the development and testing of software your organisation relies upon; your QA process will only be as good as the software it uses.
- Record what software and versions of software are used to process files so that you can identify content that may have been affected by software later found to be defective. Keep in mind that modular software, such as JHOVE, may also require you to record versions of modules used as well as the main software.
- Preserve the original files to revert back to; particularly important for workflows involving migrations or modifications to files.
- Preserve the software that you use so that you can always refer back to it and replicate historic workflows if necessary.

